搜索到
30
篇与
WD1016
的结果
返回首页
-
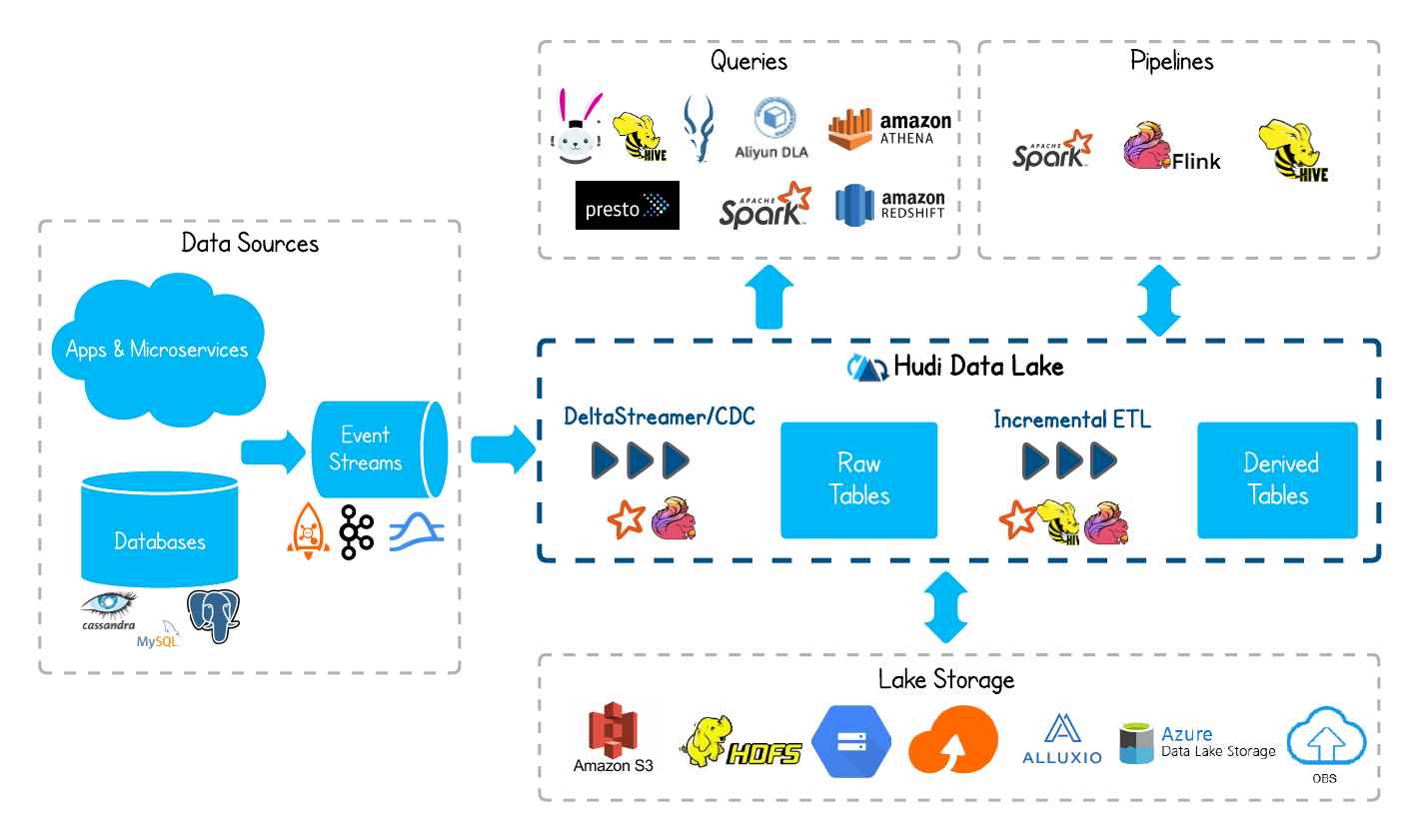
![Flink on Kubernetes 计算和存储分离实践]() Flink on Kubernetes 计算和存储分离实践 云原生已成为业界的主要趋势之一。将Flink从Yarn迁移到Kubernetes平台带来了许多优势。在这种架构下,将计算和存储解耦,计算部分运行在Kubernetes上,而存储则使用HDFS等分布式存储系统。这样的架构优势在于可以根据实际情况独立调整计算和存储资源,从而提高整体的效率和弹性。本文将介绍四种Flink在Kubernetes上的部署模式。其中,两种是基于Native Kubernetes部署的,分别有Session模式和Application模式。另外两种是基于Flink Kubernetes Operator部署的,同样包括Session模式和Application模式。首先介绍基于Flink Kubernetes Operator部署的Application模式。如果要运行自己编写的jar包,需要先构建一个镜像。如果使用了HDFS、Hudi等其他组件,还需要在Dockerfile中将Hadoop客户端和配置文件复制到镜像中,并设置相应的环境变量。同时,将所有依赖的jar包复制到Flink Home的lib目录下。FROM flink:1.16.1-scala_2.12 USER root RUN rm -f /etc/localtime && ln -sv /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo "Asia/Shanghai" > /etc/timezone ADD hadoop-3.1.1.tar.gz /opt ADD jdk1.8.0_121.tar.gz /opt RUN rm /opt/hadoop-3.1.1/share/hadoop/common/lib/commons-math3-3.1.1.jar RUN rm /opt/hadoop-3.1.1/share/hadoop/hdfs/lib/commons-math3-3.1.1.jar COPY commons-math3-3.6.1.jar /opt/hadoop-3.1.1/share/hadoop/common/lib/ COPY commons-math3-3.6.1.jar /opt/hadoop-3.1.1/share/hadoop/hdfs/lib/ RUN chmod -R 777 /opt/hadoop-3.1.1/share/hadoop/common/lib/ RUN mkdir -p /opt/hadoop/conf/ COPY yarn-site.xml /opt/hadoop/conf/ COPY core-site.xml /opt/hadoop/conf/ COPY hdfs-site.xml /opt/hadoop/conf/ COPY flink-shaded-hadoop-3-uber-3.1.1.7.0.3.0-79-7.0.jar $FLINK_HOME/lib/ COPY commons-cli-1.5.0.jar $FLINK_HOME/lib/ RUN mkdir $FLINK_HOME/mylib COPY xxx-1.0-SNAPSHOT.jar $FLINK_HOME/mylib RUN chown -R flink:flink $FLINK_HOME/mylib RUN echo 'export JAVA_HOME=/opt/jdk1.8.0_121 \n\ export HADOOP_HOME=/opt/hadoop-3.1.1 \n\ PATH=$PATH:$JAVA_HOME/bin \n\ PATH=$PATH:$HADOOP_HOME/bin'\ >> ~/.bashrc EXPOSE 8081构建镜像,在Dockerfile所在的目录中执行以下命令,确保该目录包含用于构建镜像的文件。docker build -t flink-native/flink-on-k8s-xxxx .安装helmcurl https://baltocdn.com/helm/signing.asc | sudo apt-key add -sudo apt-get install apt-transport-https --yes echo "deb https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list sudo apt-get update sudo apt-get install helm安装cert-manager组件,由它提供证书服务。kubectl create -f https://github.com/jetstack/cert-manager/releases/download/v1.8.2/cert-manager.yaml安装Flink Kubernetes Operatorhelm repo add flink-operator-repo https://downloads.apache.org/flink/flink-kubernetes-operator-1.4.0/ helm install flink-kubernetes-operator flink-operator-repo/flink-kubernetes-operator --namespace flink --create-namespace执行上述命令后,将会从ghcr.io/apache/flink-kubernetes-operator:7fc23a1镜像仓库拉取镜像。由于下载速度较慢,可以尝试从apache/flink-kubernetes-operator:7fc23a1仓库拉取镜像,然后为其添加标签docker tag apache/flink-kubernetes-operator:7fc23a1 ghcr.io/apache/flink-kubernetes-operator:7fc23a1如果在重新安装时遇到使用kubectl delete无法删除的情况,可以尝试以下命令来实现删除操作:kubectl patch crd/flinksessionjobs.flink.apache.org -p '{"metadata":{"finalizers":[]}}' --type=merge通过执行上述命令,可以成功删除该资源。查看自定义资源 kubectl get customresourcedefinition构建一个YAML文件来提交任务。其中,image指定了镜像,jarURI指定了jar包在镜像中的位置,entryClass指定了要执行的类,args指定了该类所需的参数:kind: FlinkDeployment metadata: name: flink-application-xxx spec: image: flink-native/flink-on-k8s-xxxx flinkVersion: v1_16 flinkConfiguration: taskmanager.numberOfTaskSlots: "n" serviceAccount: flink jobManager: resource: memory: "nm" cpu: n taskManager: resource: memory: "nm" cpu: n job: jarURI: local:///opt/flink/mylib/xxx-1.0-SNAPSHOT.jar entryClass: com.xxx.run.XXXJob parallelism: n upgradeMode: stateless args: ["hdfs://host:9000/data/input","hdfs://host:9000/data/output","n"]提交任务kubectl create -f xxx.yaml查看flinkdeployment kubectl get flinkdeployment查看日志kubectl logs -f deploy/flink-application-xxx{lamp/}Flink on K8S Session模式和Application模式需要安装Flink客户端,下载flink压缩包,解压即可设置命名空间首选项、赋权等kubectl create ns flink-native kubectl config set-context --current --namespace=flink-native kubectl create serviceaccount flink kubectl create clusterrolebinding flink-role-binding-flink --clusterrole=cluster-admin --serviceaccount=flink-native:flink --namespace=flink-nativeSession模式,启动Flink集群bin/kubernetes-session.sh \ -Dkubernetes.cluster-id=xxx\ -Dkubernetes.container.image=flink-native/flink-on-k8s-xxxx \ -Dkubernetes.namespace=flink-native\ -Dkubernetes.service-account=flink \ -Dclassloader.check-leaked-classloader=false \ -Dkubernetes.rest-service.exposed.type=ClusterIP \ -Dtaskmanager.memory.process.size=4096m \ -Dkubernetes.taskmanager.cpu=2 \ -Dtaskmanager.numberOfTaskSlots=4 \ -Dresourcemanager.taskmanager-timeout=60000 \ -Dkubernetes.container-start-command-template="%java% %classpath% %jvmmem% %jvmopts% %logging% %class% %args%"端口转发nohup kubectl -n flink-native port-forward --address 0.0.0.0 service/my-first-flink-cluster-rest 8081:8081 >port-forward.log &打开Flink Web UI,可以看到此时只有jobmanager向集群提交任务,运行测试任务bin/flink run -e kubernetes-session -Dkubernetes.namespace=flink-native -Dkubernetes.container.image=flink-native/flink-on-k8s-xxxx -Dkubernetes.rest-service.exposed.type=NodePort -Dkubernetes.cluster-id=my-first-flink-cluster examples/streaming/TopSpeedWindowing.jar运行自己的jar包bin/flink run -e kubernetes-session \ -Dkubernetes.namespace=flink-native \ -Dkubernetes.rest-service.exposed.type=NodePort \ -Dkubernetes.cluster-id=xxx \ -c com.xxx.run.XXXJob \ mylib/xxx-1.0-SNAPSHOT.jar hdfs://host:9000/data/input hdfs://host:9000/data/output 2查看pod,此时可以看到生成了taskmanagerkubectl get pod -o wide -A查看日志,使用以下命令可以看到测试程序TopSpeedWindowing的输出结果kubectl logs my-first-flink-cluster-taskmanager-1-1 -n flink-native查看任务列表:bin/flink list --target kubernetes-session -Dkubernetes.namespace=flink-native -Dkubernetes.jobmanager.service-account=flink -Dkubernetes.cluster-id=xxx 根据ID删除任务:bin/flink cancel --target kubernetes-session -Dkubernetes.namespace=flink-native -Dkubernetes.jobmanager.service-account=flink -Dkubernetes.cluster-id=xxxxr 3ff3c5a5e3c2f47e024e2771dc108f77Application模式bin/flink run-application \ --target kubernetes-application \ -Dkubernetes.cluster-id=xxx\ -Dkubernetes.container.image=flink-native/flink-on-k8s-xxxx \ -Dkubernetes.namespace=flink-native\ -Dkubernetes.service-account=flink \ -Dclassloader.check-leaked-classloader=false \ -Dkubernetes.rest-service.exposed.type=ClusterIP \ -c com.sohu.longuserprofile.run.TestJob \ local:///opt/flink/mylib/xxx-1.0-SNAPSHOT.jar hdfs://host:9000/data/input hdfs://host:9000/data/output 2Session模式只能提交本地(宿主机)jar包,Application模式只能使用local:///{lamp/}常用命令k8s web ui 登录token获取 kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep dashboard-admin | awk '{print $1}') | grep token: 查看所有pod列表 kubectl get pod -o wide -A 查看pod详细信息 kubectl describe pod pod_name -n flink-native 删除deployment kubectl delete deployment/my-first-flink-cluster 进入pod kubectl exec -it -n flink-native pod_name /bin/bash 获得所有命名空间 kubectl get namespace 拷贝出来 kubectl cp -n application psqls-0:/var/lib/postgresql/data/pg_wal /home 拷贝进去 kubectl cp /home/dades/pg_wal -n application psqls-0:/var/lib/postgresql/data/pg_wal
Flink on Kubernetes 计算和存储分离实践 云原生已成为业界的主要趋势之一。将Flink从Yarn迁移到Kubernetes平台带来了许多优势。在这种架构下,将计算和存储解耦,计算部分运行在Kubernetes上,而存储则使用HDFS等分布式存储系统。这样的架构优势在于可以根据实际情况独立调整计算和存储资源,从而提高整体的效率和弹性。本文将介绍四种Flink在Kubernetes上的部署模式。其中,两种是基于Native Kubernetes部署的,分别有Session模式和Application模式。另外两种是基于Flink Kubernetes Operator部署的,同样包括Session模式和Application模式。首先介绍基于Flink Kubernetes Operator部署的Application模式。如果要运行自己编写的jar包,需要先构建一个镜像。如果使用了HDFS、Hudi等其他组件,还需要在Dockerfile中将Hadoop客户端和配置文件复制到镜像中,并设置相应的环境变量。同时,将所有依赖的jar包复制到Flink Home的lib目录下。FROM flink:1.16.1-scala_2.12 USER root RUN rm -f /etc/localtime && ln -sv /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo "Asia/Shanghai" > /etc/timezone ADD hadoop-3.1.1.tar.gz /opt ADD jdk1.8.0_121.tar.gz /opt RUN rm /opt/hadoop-3.1.1/share/hadoop/common/lib/commons-math3-3.1.1.jar RUN rm /opt/hadoop-3.1.1/share/hadoop/hdfs/lib/commons-math3-3.1.1.jar COPY commons-math3-3.6.1.jar /opt/hadoop-3.1.1/share/hadoop/common/lib/ COPY commons-math3-3.6.1.jar /opt/hadoop-3.1.1/share/hadoop/hdfs/lib/ RUN chmod -R 777 /opt/hadoop-3.1.1/share/hadoop/common/lib/ RUN mkdir -p /opt/hadoop/conf/ COPY yarn-site.xml /opt/hadoop/conf/ COPY core-site.xml /opt/hadoop/conf/ COPY hdfs-site.xml /opt/hadoop/conf/ COPY flink-shaded-hadoop-3-uber-3.1.1.7.0.3.0-79-7.0.jar $FLINK_HOME/lib/ COPY commons-cli-1.5.0.jar $FLINK_HOME/lib/ RUN mkdir $FLINK_HOME/mylib COPY xxx-1.0-SNAPSHOT.jar $FLINK_HOME/mylib RUN chown -R flink:flink $FLINK_HOME/mylib RUN echo 'export JAVA_HOME=/opt/jdk1.8.0_121 \n\ export HADOOP_HOME=/opt/hadoop-3.1.1 \n\ PATH=$PATH:$JAVA_HOME/bin \n\ PATH=$PATH:$HADOOP_HOME/bin'\ >> ~/.bashrc EXPOSE 8081构建镜像,在Dockerfile所在的目录中执行以下命令,确保该目录包含用于构建镜像的文件。docker build -t flink-native/flink-on-k8s-xxxx .安装helmcurl https://baltocdn.com/helm/signing.asc | sudo apt-key add -sudo apt-get install apt-transport-https --yes echo "deb https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list sudo apt-get update sudo apt-get install helm安装cert-manager组件,由它提供证书服务。kubectl create -f https://github.com/jetstack/cert-manager/releases/download/v1.8.2/cert-manager.yaml安装Flink Kubernetes Operatorhelm repo add flink-operator-repo https://downloads.apache.org/flink/flink-kubernetes-operator-1.4.0/ helm install flink-kubernetes-operator flink-operator-repo/flink-kubernetes-operator --namespace flink --create-namespace执行上述命令后,将会从ghcr.io/apache/flink-kubernetes-operator:7fc23a1镜像仓库拉取镜像。由于下载速度较慢,可以尝试从apache/flink-kubernetes-operator:7fc23a1仓库拉取镜像,然后为其添加标签docker tag apache/flink-kubernetes-operator:7fc23a1 ghcr.io/apache/flink-kubernetes-operator:7fc23a1如果在重新安装时遇到使用kubectl delete无法删除的情况,可以尝试以下命令来实现删除操作:kubectl patch crd/flinksessionjobs.flink.apache.org -p '{"metadata":{"finalizers":[]}}' --type=merge通过执行上述命令,可以成功删除该资源。查看自定义资源 kubectl get customresourcedefinition构建一个YAML文件来提交任务。其中,image指定了镜像,jarURI指定了jar包在镜像中的位置,entryClass指定了要执行的类,args指定了该类所需的参数:kind: FlinkDeployment metadata: name: flink-application-xxx spec: image: flink-native/flink-on-k8s-xxxx flinkVersion: v1_16 flinkConfiguration: taskmanager.numberOfTaskSlots: "n" serviceAccount: flink jobManager: resource: memory: "nm" cpu: n taskManager: resource: memory: "nm" cpu: n job: jarURI: local:///opt/flink/mylib/xxx-1.0-SNAPSHOT.jar entryClass: com.xxx.run.XXXJob parallelism: n upgradeMode: stateless args: ["hdfs://host:9000/data/input","hdfs://host:9000/data/output","n"]提交任务kubectl create -f xxx.yaml查看flinkdeployment kubectl get flinkdeployment查看日志kubectl logs -f deploy/flink-application-xxx{lamp/}Flink on K8S Session模式和Application模式需要安装Flink客户端,下载flink压缩包,解压即可设置命名空间首选项、赋权等kubectl create ns flink-native kubectl config set-context --current --namespace=flink-native kubectl create serviceaccount flink kubectl create clusterrolebinding flink-role-binding-flink --clusterrole=cluster-admin --serviceaccount=flink-native:flink --namespace=flink-nativeSession模式,启动Flink集群bin/kubernetes-session.sh \ -Dkubernetes.cluster-id=xxx\ -Dkubernetes.container.image=flink-native/flink-on-k8s-xxxx \ -Dkubernetes.namespace=flink-native\ -Dkubernetes.service-account=flink \ -Dclassloader.check-leaked-classloader=false \ -Dkubernetes.rest-service.exposed.type=ClusterIP \ -Dtaskmanager.memory.process.size=4096m \ -Dkubernetes.taskmanager.cpu=2 \ -Dtaskmanager.numberOfTaskSlots=4 \ -Dresourcemanager.taskmanager-timeout=60000 \ -Dkubernetes.container-start-command-template="%java% %classpath% %jvmmem% %jvmopts% %logging% %class% %args%"端口转发nohup kubectl -n flink-native port-forward --address 0.0.0.0 service/my-first-flink-cluster-rest 8081:8081 >port-forward.log &打开Flink Web UI,可以看到此时只有jobmanager向集群提交任务,运行测试任务bin/flink run -e kubernetes-session -Dkubernetes.namespace=flink-native -Dkubernetes.container.image=flink-native/flink-on-k8s-xxxx -Dkubernetes.rest-service.exposed.type=NodePort -Dkubernetes.cluster-id=my-first-flink-cluster examples/streaming/TopSpeedWindowing.jar运行自己的jar包bin/flink run -e kubernetes-session \ -Dkubernetes.namespace=flink-native \ -Dkubernetes.rest-service.exposed.type=NodePort \ -Dkubernetes.cluster-id=xxx \ -c com.xxx.run.XXXJob \ mylib/xxx-1.0-SNAPSHOT.jar hdfs://host:9000/data/input hdfs://host:9000/data/output 2查看pod,此时可以看到生成了taskmanagerkubectl get pod -o wide -A查看日志,使用以下命令可以看到测试程序TopSpeedWindowing的输出结果kubectl logs my-first-flink-cluster-taskmanager-1-1 -n flink-native查看任务列表:bin/flink list --target kubernetes-session -Dkubernetes.namespace=flink-native -Dkubernetes.jobmanager.service-account=flink -Dkubernetes.cluster-id=xxx 根据ID删除任务:bin/flink cancel --target kubernetes-session -Dkubernetes.namespace=flink-native -Dkubernetes.jobmanager.service-account=flink -Dkubernetes.cluster-id=xxxxr 3ff3c5a5e3c2f47e024e2771dc108f77Application模式bin/flink run-application \ --target kubernetes-application \ -Dkubernetes.cluster-id=xxx\ -Dkubernetes.container.image=flink-native/flink-on-k8s-xxxx \ -Dkubernetes.namespace=flink-native\ -Dkubernetes.service-account=flink \ -Dclassloader.check-leaked-classloader=false \ -Dkubernetes.rest-service.exposed.type=ClusterIP \ -c com.sohu.longuserprofile.run.TestJob \ local:///opt/flink/mylib/xxx-1.0-SNAPSHOT.jar hdfs://host:9000/data/input hdfs://host:9000/data/output 2Session模式只能提交本地(宿主机)jar包,Application模式只能使用local:///{lamp/}常用命令k8s web ui 登录token获取 kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep dashboard-admin | awk '{print $1}') | grep token: 查看所有pod列表 kubectl get pod -o wide -A 查看pod详细信息 kubectl describe pod pod_name -n flink-native 删除deployment kubectl delete deployment/my-first-flink-cluster 进入pod kubectl exec -it -n flink-native pod_name /bin/bash 获得所有命名空间 kubectl get namespace 拷贝出来 kubectl cp -n application psqls-0:/var/lib/postgresql/data/pg_wal /home 拷贝进去 kubectl cp /home/dades/pg_wal -n application psqls-0:/var/lib/postgresql/data/pg_wal -
![Flink 任务执行流程源码解析]() Flink 任务执行流程源码解析 用户提交Flink任务时,通过先后调用transform()——>doTransform()——>addOperator()方法,将map、flatMap、filter、process等算子添加到List<Transformation<?>> transformations集合中。在执行execute()方法时,会使用StreamGraphGenerator的generate()方法构建流拓扑StreamGraph(即Pipeline),数据结构属于有向无环图。在StreamGraph中,StreamNode用于记录算子信息,而StreamEdge则用于记录数据交换方式,包括以下几种Partitioner:{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}Partitioner类都是StreamPartitioner类的子类,它们通过实现isPointwise()方法来确定自身的类型。一种是ALL_TO_ALL,另一个种是POINTWISE。/** * A distribution pattern determines, which sub tasks of a producing task are connected to which * consuming sub tasks. * * <p>It affects how {@link ExecutionVertex} and {@link IntermediateResultPartition} are connected * in {@link EdgeManagerBuildUtil} */ public enum DistributionPattern { /** Each producing sub task is connected to each sub task of the consuming task. */ ALL_TO_ALL, /** Each producing sub task is connected to one or more subtask(s) of the consuming task. */ POINTWISE }ALL_TO_ALL意味着上游的每个subtask需要与下游的每个subtask建立连接。{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}POINTWISE则是上游的每个subtask和下游的一个或多个subtask连接。{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}StreamGraph构建完成后,,会通过 PipelineExecutorUtils.getJobGraph()构建JobGraph,具体流程是:——>PipelineExecutorUtils.getJobGraph() ——>FlinkPipelineTranslationUtil.getJobGraph() ——>StreamGraphTranslator.translateToJobGraph() ——>StreamGraph.getJobGraph() ——>StreamingJobGraphGenerator.createJobGraph()JobGraph是优化后的StreamGraph,如果相连的算子支持chaining,合并到一个StreamNode,chaining在StreamingJobGraphGenerator的setChaining()方法中实现:/** * Sets up task chains from the source {@link StreamNode} instances. * * <p>This will recursively create all {@link JobVertex} instances. */ private void setChaining(Map<Integer, byte[]> hashes, List<Map<Integer, byte[]>> legacyHashes) { // we separate out the sources that run as inputs to another operator (chained inputs) // from the sources that needs to run as the main (head) operator. final Map<Integer, OperatorChainInfo> chainEntryPoints = buildChainedInputsAndGetHeadInputs(hashes, legacyHashes); final Collection<OperatorChainInfo> initialEntryPoints = chainEntryPoints.entrySet().stream() .sorted(Comparator.comparing(Map.Entry::getKey)) .map(Map.Entry::getValue) .collect(Collectors.toList()); // iterate over a copy of the values, because this map gets concurrently modified for (OperatorChainInfo info : initialEntryPoints) { createChain( info.getStartNodeId(), 1, // operators start at position 1 because 0 is for chained source inputs info, chainEntryPoints); } }将符合chaining条件的,合并到一个StreamNode条件如下:1. 下游节点输入边只有一个 2. 与下游属于同一个SlotSharingGroup 3. 数据分发策略Forward 4. 流数据交换模式不是批量模式 5. 上下游并行度相等 6. StreamGraph中chaining为true streamGraph 是可以 chain的 7. 算子是否可以链化areOperatorsChainable代码如下:public static boolean isChainable(StreamEdge edge, StreamGraph streamGraph) { StreamNode downStreamVertex = streamGraph.getTargetVertex(edge); return downStreamVertex.getInEdges().size() == 1 && isChainableInput(edge, streamGraph); } private static boolean isChainableInput(StreamEdge edge, StreamGraph streamGraph) { StreamNode upStreamVertex = streamGraph.getSourceVertex(edge); StreamNode downStreamVertex = streamGraph.getTargetVertex(edge); if (!(upStreamVertex.isSameSlotSharingGroup(downStreamVertex) && areOperatorsChainable(upStreamVertex, downStreamVertex, streamGraph) && (edge.getPartitioner() instanceof ForwardPartitioner) && edge.getExchangeMode() != StreamExchangeMode.BATCH && upStreamVertex.getParallelism() == downStreamVertex.getParallelism() && streamGraph.isChainingEnabled())) { return false; } ... ... 从Source节点开始,使用深度优先搜索(DFS)算法递归遍历有向无环图中的所有StreamNode节点。{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}待续 ... ...
Flink 任务执行流程源码解析 用户提交Flink任务时,通过先后调用transform()——>doTransform()——>addOperator()方法,将map、flatMap、filter、process等算子添加到List<Transformation<?>> transformations集合中。在执行execute()方法时,会使用StreamGraphGenerator的generate()方法构建流拓扑StreamGraph(即Pipeline),数据结构属于有向无环图。在StreamGraph中,StreamNode用于记录算子信息,而StreamEdge则用于记录数据交换方式,包括以下几种Partitioner:{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}Partitioner类都是StreamPartitioner类的子类,它们通过实现isPointwise()方法来确定自身的类型。一种是ALL_TO_ALL,另一个种是POINTWISE。/** * A distribution pattern determines, which sub tasks of a producing task are connected to which * consuming sub tasks. * * <p>It affects how {@link ExecutionVertex} and {@link IntermediateResultPartition} are connected * in {@link EdgeManagerBuildUtil} */ public enum DistributionPattern { /** Each producing sub task is connected to each sub task of the consuming task. */ ALL_TO_ALL, /** Each producing sub task is connected to one or more subtask(s) of the consuming task. */ POINTWISE }ALL_TO_ALL意味着上游的每个subtask需要与下游的每个subtask建立连接。{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}POINTWISE则是上游的每个subtask和下游的一个或多个subtask连接。{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}StreamGraph构建完成后,,会通过 PipelineExecutorUtils.getJobGraph()构建JobGraph,具体流程是:——>PipelineExecutorUtils.getJobGraph() ——>FlinkPipelineTranslationUtil.getJobGraph() ——>StreamGraphTranslator.translateToJobGraph() ——>StreamGraph.getJobGraph() ——>StreamingJobGraphGenerator.createJobGraph()JobGraph是优化后的StreamGraph,如果相连的算子支持chaining,合并到一个StreamNode,chaining在StreamingJobGraphGenerator的setChaining()方法中实现:/** * Sets up task chains from the source {@link StreamNode} instances. * * <p>This will recursively create all {@link JobVertex} instances. */ private void setChaining(Map<Integer, byte[]> hashes, List<Map<Integer, byte[]>> legacyHashes) { // we separate out the sources that run as inputs to another operator (chained inputs) // from the sources that needs to run as the main (head) operator. final Map<Integer, OperatorChainInfo> chainEntryPoints = buildChainedInputsAndGetHeadInputs(hashes, legacyHashes); final Collection<OperatorChainInfo> initialEntryPoints = chainEntryPoints.entrySet().stream() .sorted(Comparator.comparing(Map.Entry::getKey)) .map(Map.Entry::getValue) .collect(Collectors.toList()); // iterate over a copy of the values, because this map gets concurrently modified for (OperatorChainInfo info : initialEntryPoints) { createChain( info.getStartNodeId(), 1, // operators start at position 1 because 0 is for chained source inputs info, chainEntryPoints); } }将符合chaining条件的,合并到一个StreamNode条件如下:1. 下游节点输入边只有一个 2. 与下游属于同一个SlotSharingGroup 3. 数据分发策略Forward 4. 流数据交换模式不是批量模式 5. 上下游并行度相等 6. StreamGraph中chaining为true streamGraph 是可以 chain的 7. 算子是否可以链化areOperatorsChainable代码如下:public static boolean isChainable(StreamEdge edge, StreamGraph streamGraph) { StreamNode downStreamVertex = streamGraph.getTargetVertex(edge); return downStreamVertex.getInEdges().size() == 1 && isChainableInput(edge, streamGraph); } private static boolean isChainableInput(StreamEdge edge, StreamGraph streamGraph) { StreamNode upStreamVertex = streamGraph.getSourceVertex(edge); StreamNode downStreamVertex = streamGraph.getTargetVertex(edge); if (!(upStreamVertex.isSameSlotSharingGroup(downStreamVertex) && areOperatorsChainable(upStreamVertex, downStreamVertex, streamGraph) && (edge.getPartitioner() instanceof ForwardPartitioner) && edge.getExchangeMode() != StreamExchangeMode.BATCH && upStreamVertex.getParallelism() == downStreamVertex.getParallelism() && streamGraph.isChainingEnabled())) { return false; } ... ... 从Source节点开始,使用深度优先搜索(DFS)算法递归遍历有向无环图中的所有StreamNode节点。{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}待续 ... ... -
![Flink实时计算问题记录与解决方案]() Flink实时计算问题记录与解决方案 当Flink任务的并行度大于Kafka分区数时,可能会导致部分并行度空闲,进而影响水位线(watermark)的生成。为了解决这个问题,可以通过设置withIdleness来进行调整:WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withIdleness(Duration.ofSeconds(60))对于withIdleness参数,应避免将下游任务设置得太小。原因在于,如果上游任务因故障停止,而其恢复所需时间超过了下游任务设置的withIdleness值,那么下游任务会将超时的分区标记为不再消费,导致数据丢失。为避免此问题,建议将分区数设置为不小于任务的并行度,并不设置withIdleness参数,这样可以有效防止潜在的数据丢失情况。{lamp/}kafkaSource指定时间戳消费时,必须为毫秒时间戳,Flink 1.14官网文档为秒,是错误的,指定后不会生效。setStartingOffsets(OffsetsInitializer.timestamp(1654703973000L)){lamp/}要实现Flink与Kafka的端到端一致性,需要确保Kafka的版本不低于2.5。要注意的是,Flink 1.14.2中flink-connector所包含的kafka-clients版本是2.4.X。because of a bug in the Kafka broker (KAFKA-9310). Please upgrade to Kafka 2.5+. If you are running with concurrent checkpoints, you also may want to try without them.Flink-Kafka端到端一致性需要设置TRANSACTIONAL_ID_CONFIG = "transactional.id",如果不设置,从checkpoint重启会报错:OutOfOrderSequenceException: The broker received an out of order sequence number。{lamp/}Flink CDC同步mysql时,需要把binlog配置成ROW模式,查看命令和配置方法如下:show variables like 'binlog_format%'; vi /etc/my.cnf binlog_format=row systemctl restart mariadb.service非ROW模式时会报以下错误:Caused by: org.apache.flink.table.api.ValidationException: The MySQL server is configured with binlog_format MIXED rather than ROW, which is required for this connector to work properly. Change the MySQL configuration to use a binlog_format=ROW and restart the connector.Flink 1.14.2版本使用CDC 2.2,需要编译CDC源码进行版本适配:1.pom文件中修改flink版本为1.14.2、scala版本为2.12.72.修改flink-table-planner-blink为flink-table-planner;flink-table-runtime-blink为flink-table-runtime3.flink-shaded-guava版本由30.1.1-jre-14.0修改为18.0-13.0修改完成后,会出现部分import报错的情况。需要根据新依赖版本中的路径和类进行相应的修改,例如,将创建TimestampFormat的代码修改为:TimestampFormat timestampOption = JsonFormatOptionsUtil.getTimestampFormat(formatOptions)。在编译过程中,首先需要使用install命令对父module进行安装。这样可以确保本地Maven仓库中包含各个子module的JAR包。对子module进行打包时,如Flink MySQL CDC,可以在子module的POM文件中修改打包方式,将所有依赖项都打包到一个JAR文件中,这样在工程中只需引入一个<dependency>即可。否则,会因为缺少某些依赖报错,如:Could not initialize class io.debezium.connector.mysql.MySqlConnectorConfig
Flink实时计算问题记录与解决方案 当Flink任务的并行度大于Kafka分区数时,可能会导致部分并行度空闲,进而影响水位线(watermark)的生成。为了解决这个问题,可以通过设置withIdleness来进行调整:WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withIdleness(Duration.ofSeconds(60))对于withIdleness参数,应避免将下游任务设置得太小。原因在于,如果上游任务因故障停止,而其恢复所需时间超过了下游任务设置的withIdleness值,那么下游任务会将超时的分区标记为不再消费,导致数据丢失。为避免此问题,建议将分区数设置为不小于任务的并行度,并不设置withIdleness参数,这样可以有效防止潜在的数据丢失情况。{lamp/}kafkaSource指定时间戳消费时,必须为毫秒时间戳,Flink 1.14官网文档为秒,是错误的,指定后不会生效。setStartingOffsets(OffsetsInitializer.timestamp(1654703973000L)){lamp/}要实现Flink与Kafka的端到端一致性,需要确保Kafka的版本不低于2.5。要注意的是,Flink 1.14.2中flink-connector所包含的kafka-clients版本是2.4.X。because of a bug in the Kafka broker (KAFKA-9310). Please upgrade to Kafka 2.5+. If you are running with concurrent checkpoints, you also may want to try without them.Flink-Kafka端到端一致性需要设置TRANSACTIONAL_ID_CONFIG = "transactional.id",如果不设置,从checkpoint重启会报错:OutOfOrderSequenceException: The broker received an out of order sequence number。{lamp/}Flink CDC同步mysql时,需要把binlog配置成ROW模式,查看命令和配置方法如下:show variables like 'binlog_format%'; vi /etc/my.cnf binlog_format=row systemctl restart mariadb.service非ROW模式时会报以下错误:Caused by: org.apache.flink.table.api.ValidationException: The MySQL server is configured with binlog_format MIXED rather than ROW, which is required for this connector to work properly. Change the MySQL configuration to use a binlog_format=ROW and restart the connector.Flink 1.14.2版本使用CDC 2.2,需要编译CDC源码进行版本适配:1.pom文件中修改flink版本为1.14.2、scala版本为2.12.72.修改flink-table-planner-blink为flink-table-planner;flink-table-runtime-blink为flink-table-runtime3.flink-shaded-guava版本由30.1.1-jre-14.0修改为18.0-13.0修改完成后,会出现部分import报错的情况。需要根据新依赖版本中的路径和类进行相应的修改,例如,将创建TimestampFormat的代码修改为:TimestampFormat timestampOption = JsonFormatOptionsUtil.getTimestampFormat(formatOptions)。在编译过程中,首先需要使用install命令对父module进行安装。这样可以确保本地Maven仓库中包含各个子module的JAR包。对子module进行打包时,如Flink MySQL CDC,可以在子module的POM文件中修改打包方式,将所有依赖项都打包到一个JAR文件中,这样在工程中只需引入一个<dependency>即可。否则,会因为缺少某些依赖报错,如:Could not initialize class io.debezium.connector.mysql.MySqlConnectorConfig -
![构建智能灵活的 Ribbon 负载均衡策略]() 构建智能灵活的 Ribbon 负载均衡策略 分布式系统架构中,负载均衡是确保系统高可用性和性能的关键环节。以线上服务为例,某个服务原本部署了4个实例来应对大量的请求流量。然而,意外情况发生,其中一个实例所在的机房出现故障,导致其响应速度变得极为缓慢,但是仍然和Nacos注册中心保持着心跳。而当时所采用的负载均衡策略是轮询策略 RoundRobinRule,这一策略在正常情况下能够较为均匀地分配请求,但在面对这种异常情况时,却暴露出了明显的局限性。由于轮询策略的特性,它不会根据实例的实际响应情况进行动态调整,这就使得故障实例上仍然会有大量请求持续堆积。随着时间的推移,发现该实例所在机器的 close_wait 连接数急剧增加,导致整个机器负载加重。为了解决这一问题,调研了一些传统的应对策略:其一,配置超时失败重试机制 ... httpclient: response-timeout: 30s。故障实例响应慢时,自动失败路由到其他实例进行重试,从而使上游的请求最终能够成功。但故障服务实例的流量并没有得到有效的控制和调整。这意味着故障实例和所在机器仍然在承受着巨大的压力。其二,采用熔断策略 Sentinel、Resilience4J、Hystrix。在响应时间/出错百分比/线程数等达到阈值时进行降级、熔断,以保护其他服务实例不受影响。然而,在该场景中,由于还有 3/4 的实例处于正常可用状态,直接进行熔断操作显得过于激进。其三,考虑使用权重轮询策略 WeightedResponseTimeRule。根据服务实例的性能表现动态地分配权重,性能好的实例会被分配更多的请求,而性能差的实例则会逐渐减少请求分配。但该场景下,故障机器的响应时间与正常服务相比已经不在一个数量级,其 QPS 却依然很高。这就导致在权重轮询策略下,故障机器的服务权重会迅速降低,几乎不再接收请求。而且由于我们的配置是在网关层面,当故障机器恢复后,系统无法自动重新计算权重,使得分配到故障机器的流量很少,其权重也很难再次提升上去。基于以上困境,决定对权重轮询策略进行二次开发,使其更加智能,以最大限度地减小请求端的影响。首先增加过滤器RibbonResponseFilter。这个过滤器的主要作用是计算每个服务实例的响应时间,并将其记录到 ServerStats 中。同时,它还会记录请求的返回状态,如果返回状态不是 200,就将其转化为请求超时,并相应地减小该服务的权重。@Component @Slf4j public class RibbonResponseFilter implements GlobalFilter, Ordered { @Autowired protected final SpringClientFactory springClientFactory; public static final String RQUEST_START_TIME = "RequestStartTime"; public static final double TIME_WEIGHT = 30000; public RibbonResponseFilter(SpringClientFactory springClientFactory) { this.springClientFactory = springClientFactory; } @Override public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { exchange.getAttributes().put(RQUEST_START_TIME, System.currentTimeMillis()); return chain.filter(exchange).then(Mono.fromRunnable(() -> { URI requestUrl = exchange.getAttribute(ServerWebExchangeUtils.GATEWAY_REQUEST_URL_ATTR); Route route = exchange.getAttribute(ServerWebExchangeUtils.GATEWAY_ROUTE_ATTR); LoadBalancerContext loadBalancerContext = this.springClientFactory.getLoadBalancerContext(route.getUri().getHost()); ServerStats stats = loadBalancerContext.getServerStats(new Server(requestUrl.getHost(), requestUrl.getPort())); long orgStartTime = exchange.getAttribute(RQUEST_START_TIME); long time = System.currentTimeMillis() - orgStartTime; // 响应时间超过 5s 或者服务异常时,减小权重 if (exchange.getResponse().getStatusCode().value()!= 200 || time > 5000) { log.info("The abnormal response will lead to a decrease in weight : {} ", requestUrl.getHost()); stats.noteResponseTime(TIME_WEIGHT); } })); } @Override public int getOrder() { return Ordered.LOWEST_PRECEDENCE; } }增加这个过滤器的原因在于,无论是使用自定义的负载均衡策略,还是内置的 WeightedResponseTimeRule,都无法自动获取到每个服务实例的总请求次数、异常请求次数以及响应时间等关键参数。通过这个过滤器,能够有效地收集这些信息,为后续的权重计算和调整提供有力的数据支持。在注册权重更新 Timer(默认 30s)的同时,同时注册了一个权重重置 Timer(5m)。这样一来,当故障服务实例恢复后,在 5 分钟内,它就能够重新参与到负载均衡的分配中。以下是相关的代码片段:void resetWeight() { if (resetWeightTimer!= null) { resetWeightTimer.cancel(); } resetWeightTimer = new Timer("NFLoadBalancer-AutoRobinRule-resetWeightTimer-" + name, true); resetWeightTimer.schedule(new ResetServerWeightTask(), 0, 60 * 1000 * 5); ResetServerWeight rsw = new ResetServerWeight(); rsw.maintainWeights(); Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() { public void run() { logger.info("Stopping NFLoadBalancer-AutoRobinRule-ResetWeightTimer-" + name); resetWeightTimer.cancel(); } })); } public void maintainWeights() { ILoadBalancer lb = getLoadBalancer(); if (lb == null) { return; } if (!resetServerWeightAssignmentInProgress.compareAndSet(false, true)) { return; } try { logger.info("Reset weight job started"); AbstractLoadBalancer nlb = (AbstractLoadBalancer) lb; LoadBalancerStats stats = nlb.getLoadBalancerStats(); if (stats == null) { return; } Double weightSoFar = 0.0; List<Double> finalWeights = new ArrayList<Double>(); for (Server server : nlb.getAllServers()) { finalWeights.add(weightSoFar); } setWeights(finalWeights); } catch (Exception e) { logger.error("Error reset server weights", e); } finally { resetServerWeightAssignmentInProgress.set(false); } }在采用此负载均衡策略时,若重置权重后服务仍未修复,由于配置了超时重试机制,请求端可毫无察觉。与此同时,该服务实例的权重会迅速在短时间内再次降至极低水平,如此循环,直至实例恢复正常。此策略有效地处理了线上服务可能遭遇的各类异常状况。
构建智能灵活的 Ribbon 负载均衡策略 分布式系统架构中,负载均衡是确保系统高可用性和性能的关键环节。以线上服务为例,某个服务原本部署了4个实例来应对大量的请求流量。然而,意外情况发生,其中一个实例所在的机房出现故障,导致其响应速度变得极为缓慢,但是仍然和Nacos注册中心保持着心跳。而当时所采用的负载均衡策略是轮询策略 RoundRobinRule,这一策略在正常情况下能够较为均匀地分配请求,但在面对这种异常情况时,却暴露出了明显的局限性。由于轮询策略的特性,它不会根据实例的实际响应情况进行动态调整,这就使得故障实例上仍然会有大量请求持续堆积。随着时间的推移,发现该实例所在机器的 close_wait 连接数急剧增加,导致整个机器负载加重。为了解决这一问题,调研了一些传统的应对策略:其一,配置超时失败重试机制 ... httpclient: response-timeout: 30s。故障实例响应慢时,自动失败路由到其他实例进行重试,从而使上游的请求最终能够成功。但故障服务实例的流量并没有得到有效的控制和调整。这意味着故障实例和所在机器仍然在承受着巨大的压力。其二,采用熔断策略 Sentinel、Resilience4J、Hystrix。在响应时间/出错百分比/线程数等达到阈值时进行降级、熔断,以保护其他服务实例不受影响。然而,在该场景中,由于还有 3/4 的实例处于正常可用状态,直接进行熔断操作显得过于激进。其三,考虑使用权重轮询策略 WeightedResponseTimeRule。根据服务实例的性能表现动态地分配权重,性能好的实例会被分配更多的请求,而性能差的实例则会逐渐减少请求分配。但该场景下,故障机器的响应时间与正常服务相比已经不在一个数量级,其 QPS 却依然很高。这就导致在权重轮询策略下,故障机器的服务权重会迅速降低,几乎不再接收请求。而且由于我们的配置是在网关层面,当故障机器恢复后,系统无法自动重新计算权重,使得分配到故障机器的流量很少,其权重也很难再次提升上去。基于以上困境,决定对权重轮询策略进行二次开发,使其更加智能,以最大限度地减小请求端的影响。首先增加过滤器RibbonResponseFilter。这个过滤器的主要作用是计算每个服务实例的响应时间,并将其记录到 ServerStats 中。同时,它还会记录请求的返回状态,如果返回状态不是 200,就将其转化为请求超时,并相应地减小该服务的权重。@Component @Slf4j public class RibbonResponseFilter implements GlobalFilter, Ordered { @Autowired protected final SpringClientFactory springClientFactory; public static final String RQUEST_START_TIME = "RequestStartTime"; public static final double TIME_WEIGHT = 30000; public RibbonResponseFilter(SpringClientFactory springClientFactory) { this.springClientFactory = springClientFactory; } @Override public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { exchange.getAttributes().put(RQUEST_START_TIME, System.currentTimeMillis()); return chain.filter(exchange).then(Mono.fromRunnable(() -> { URI requestUrl = exchange.getAttribute(ServerWebExchangeUtils.GATEWAY_REQUEST_URL_ATTR); Route route = exchange.getAttribute(ServerWebExchangeUtils.GATEWAY_ROUTE_ATTR); LoadBalancerContext loadBalancerContext = this.springClientFactory.getLoadBalancerContext(route.getUri().getHost()); ServerStats stats = loadBalancerContext.getServerStats(new Server(requestUrl.getHost(), requestUrl.getPort())); long orgStartTime = exchange.getAttribute(RQUEST_START_TIME); long time = System.currentTimeMillis() - orgStartTime; // 响应时间超过 5s 或者服务异常时,减小权重 if (exchange.getResponse().getStatusCode().value()!= 200 || time > 5000) { log.info("The abnormal response will lead to a decrease in weight : {} ", requestUrl.getHost()); stats.noteResponseTime(TIME_WEIGHT); } })); } @Override public int getOrder() { return Ordered.LOWEST_PRECEDENCE; } }增加这个过滤器的原因在于,无论是使用自定义的负载均衡策略,还是内置的 WeightedResponseTimeRule,都无法自动获取到每个服务实例的总请求次数、异常请求次数以及响应时间等关键参数。通过这个过滤器,能够有效地收集这些信息,为后续的权重计算和调整提供有力的数据支持。在注册权重更新 Timer(默认 30s)的同时,同时注册了一个权重重置 Timer(5m)。这样一来,当故障服务实例恢复后,在 5 分钟内,它就能够重新参与到负载均衡的分配中。以下是相关的代码片段:void resetWeight() { if (resetWeightTimer!= null) { resetWeightTimer.cancel(); } resetWeightTimer = new Timer("NFLoadBalancer-AutoRobinRule-resetWeightTimer-" + name, true); resetWeightTimer.schedule(new ResetServerWeightTask(), 0, 60 * 1000 * 5); ResetServerWeight rsw = new ResetServerWeight(); rsw.maintainWeights(); Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() { public void run() { logger.info("Stopping NFLoadBalancer-AutoRobinRule-ResetWeightTimer-" + name); resetWeightTimer.cancel(); } })); } public void maintainWeights() { ILoadBalancer lb = getLoadBalancer(); if (lb == null) { return; } if (!resetServerWeightAssignmentInProgress.compareAndSet(false, true)) { return; } try { logger.info("Reset weight job started"); AbstractLoadBalancer nlb = (AbstractLoadBalancer) lb; LoadBalancerStats stats = nlb.getLoadBalancerStats(); if (stats == null) { return; } Double weightSoFar = 0.0; List<Double> finalWeights = new ArrayList<Double>(); for (Server server : nlb.getAllServers()) { finalWeights.add(weightSoFar); } setWeights(finalWeights); } catch (Exception e) { logger.error("Error reset server weights", e); } finally { resetServerWeightAssignmentInProgress.set(false); } }在采用此负载均衡策略时,若重置权重后服务仍未修复,由于配置了超时重试机制,请求端可毫无察觉。与此同时,该服务实例的权重会迅速在短时间内再次降至极低水平,如此循环,直至实例恢复正常。此策略有效地处理了线上服务可能遭遇的各类异常状况。 -
![调度系统核心服务迁移方案演进]() 调度系统核心服务迁移方案演进 系统使用Zookeeper进行主从服务选举,对于频繁更新数据库的服务S1和S2,迁移操作需要确保高可用性并且不容忍数据丢失。首先,对数据库进行扩展,引入DB3。要确保DB3的数据与主数据库DB1和从数据库DB2完全一致,需要执行库锁操作。由于服务对数据库的操作不支持等待或失败重试,所以无法对主数据库进行锁定。因此,考虑了以下方案:1.对DB2进行锁库,此时DB2是静态的flush tables with read lock;2.将DB2的历史数据导入DB3主:bin/mysqldump -urecom recom -p >recom.sql 从:bin/mysql -u recom -p recom < recom.sql3.将DB3的Master指向DB2show master status; change master to master_host='10.*.*.*',master_user='un',master_password='pwd123',master_log_file='/opt/mysql_data/binlog.000068',master_log_pos=117844696; start slave; show slave status \G;4.然后解锁DB2,此时延迟同步的数据会同步到DB2,DB2再同步到DB3,从而保证了三个数据库完全一致unlock tables;使用同样的方式,可以扩展DB4,形成链式复制。在将服务配置切换到新的数据库时,主库的切换可能会带来一些问题。由于每个服务都有独立的配置,无法同时对所有服务进行配置更新。后续如果引入NACOS,通过配置热更新可以使迁移变得更加简单。因此,在修改某个服务的主库之前,需要考虑以下情况:假设S1和S2的配置分别为DB1和DB2。现在要切换S2的配置。当S2的主库发生改变后,在切换其他服务的主库之前,可能会出现同时向DB1和DB2/DB3进行更新的情况。这意味着DB1更新的数据会同步到DB2和DB3,但是DB2和DB3更新的数据无法同步到DB1。如果一个请求到达S2并在DB2/DB3中插入了一条数据,接下来的请求到达S1时,当尝试更新上一个请求插入的数据时,就会发生异常。因此,链式复制可以满足数据库的扩展需求,但无法满足服务的扩展需求。在迁移过程中,存在一个关键时间点,其中两个服务可能同时对不同的数据库进行更新操作。然而,一旦更新了主从复制链中间的库,上游数据库将无法同步到最新的数据。如果希望在迁移过程中保持服务的高可用性,必须解决这个问题。需要确保无论哪个服务更新了其中一个数据库,其他数据库都能感知到这个变化。因此,考虑将链式的主从MySQL连接成一个环形结构。在实现这一点时,需要考虑以下两个问题:{card-describe title="问题"}1.在更新数据时,担心在环路上可能会导致死循环的问题。通过进行调研,发现MySQL提供了良好的支持,不会出现这种问题。2.另一个需要考虑的问题是自增主键的冲突。假设在DB1插入了一条数据,在这条数据同步之前,又在DB2插入了一条数据。这样,这两条不同数据的自增主键可能会相同。当DB1和DB2之间通过环路复制传递新增数据时,就会发生主键冲突的情况。{/card-describe}针对上述问题,需要找到解决方案来确保数据同步和主键唯一性。为了解决这个问题,可以通过设置auto_increment_offset和auto_increment_increment来控制不同库之间的自增偏移量和步长。这样,就能够在任何时间点将服务指向环形结构中的任意两个库,从而完成迁移过程。MySQL相关命令:启动和初始化 bin/mysqld --defaults-file=/opt/mysql/my.cnf --initialize --user=root --basedir=/opt/mysql --datadir=/opt/mysql_data bin/mysqld_safe --defaults-file=/opt/mysql/my.cnf --user=root & 获取root密码 cat errorlog.err | grep root@localhost 重置密码和授权 bin/mysql -u root -p set password for 'root'@'localhost' = password(''); CREATE USER 'recom'@'%' IDENTIFIED BY 'recom@123'; GRANT ALL PRIVILEGES ON *.* TO 'recom'@'%' IDENTIFIED BY 'recom@123' WITH GRANT OPTION; flush privileges; 其他命令 stop slave; reset slave all; bin/mysqladmin -uroot -p shutdown
调度系统核心服务迁移方案演进 系统使用Zookeeper进行主从服务选举,对于频繁更新数据库的服务S1和S2,迁移操作需要确保高可用性并且不容忍数据丢失。首先,对数据库进行扩展,引入DB3。要确保DB3的数据与主数据库DB1和从数据库DB2完全一致,需要执行库锁操作。由于服务对数据库的操作不支持等待或失败重试,所以无法对主数据库进行锁定。因此,考虑了以下方案:1.对DB2进行锁库,此时DB2是静态的flush tables with read lock;2.将DB2的历史数据导入DB3主:bin/mysqldump -urecom recom -p >recom.sql 从:bin/mysql -u recom -p recom < recom.sql3.将DB3的Master指向DB2show master status; change master to master_host='10.*.*.*',master_user='un',master_password='pwd123',master_log_file='/opt/mysql_data/binlog.000068',master_log_pos=117844696; start slave; show slave status \G;4.然后解锁DB2,此时延迟同步的数据会同步到DB2,DB2再同步到DB3,从而保证了三个数据库完全一致unlock tables;使用同样的方式,可以扩展DB4,形成链式复制。在将服务配置切换到新的数据库时,主库的切换可能会带来一些问题。由于每个服务都有独立的配置,无法同时对所有服务进行配置更新。后续如果引入NACOS,通过配置热更新可以使迁移变得更加简单。因此,在修改某个服务的主库之前,需要考虑以下情况:假设S1和S2的配置分别为DB1和DB2。现在要切换S2的配置。当S2的主库发生改变后,在切换其他服务的主库之前,可能会出现同时向DB1和DB2/DB3进行更新的情况。这意味着DB1更新的数据会同步到DB2和DB3,但是DB2和DB3更新的数据无法同步到DB1。如果一个请求到达S2并在DB2/DB3中插入了一条数据,接下来的请求到达S1时,当尝试更新上一个请求插入的数据时,就会发生异常。因此,链式复制可以满足数据库的扩展需求,但无法满足服务的扩展需求。在迁移过程中,存在一个关键时间点,其中两个服务可能同时对不同的数据库进行更新操作。然而,一旦更新了主从复制链中间的库,上游数据库将无法同步到最新的数据。如果希望在迁移过程中保持服务的高可用性,必须解决这个问题。需要确保无论哪个服务更新了其中一个数据库,其他数据库都能感知到这个变化。因此,考虑将链式的主从MySQL连接成一个环形结构。在实现这一点时,需要考虑以下两个问题:{card-describe title="问题"}1.在更新数据时,担心在环路上可能会导致死循环的问题。通过进行调研,发现MySQL提供了良好的支持,不会出现这种问题。2.另一个需要考虑的问题是自增主键的冲突。假设在DB1插入了一条数据,在这条数据同步之前,又在DB2插入了一条数据。这样,这两条不同数据的自增主键可能会相同。当DB1和DB2之间通过环路复制传递新增数据时,就会发生主键冲突的情况。{/card-describe}针对上述问题,需要找到解决方案来确保数据同步和主键唯一性。为了解决这个问题,可以通过设置auto_increment_offset和auto_increment_increment来控制不同库之间的自增偏移量和步长。这样,就能够在任何时间点将服务指向环形结构中的任意两个库,从而完成迁移过程。MySQL相关命令:启动和初始化 bin/mysqld --defaults-file=/opt/mysql/my.cnf --initialize --user=root --basedir=/opt/mysql --datadir=/opt/mysql_data bin/mysqld_safe --defaults-file=/opt/mysql/my.cnf --user=root & 获取root密码 cat errorlog.err | grep root@localhost 重置密码和授权 bin/mysql -u root -p set password for 'root'@'localhost' = password(''); CREATE USER 'recom'@'%' IDENTIFIED BY 'recom@123'; GRANT ALL PRIVILEGES ON *.* TO 'recom'@'%' IDENTIFIED BY 'recom@123' WITH GRANT OPTION; flush privileges; 其他命令 stop slave; reset slave all; bin/mysqladmin -uroot -p shutdown