搜索到
30
篇与
WD1016
的结果
返回首页
-
![JAVA垃圾回收]() JAVA垃圾回收 垃圾回收算法 标记-清除算法 :产生不连续的内存碎片,为较大对象分配内存时无法找到足够连续的内存,不得不提前触发垃圾收集动作。CMS垃圾回收器。标记-整理算法 :存活的对象向一端移动,存活率高时,效率远高于复制算法。G1、ParallelGC(Paraller Old)。复制算法 :Eden、s0、s1,比例是8:1:1,10%被浪费,JDK8,ParallelGC(Parallel Scavenge)。分代收集算法 。{lamp/}垃圾回收器 CMS收集器 :发标记、并发清除、内存碎片、最短回收停顿时间为目标,与用户线程可以并发执行,牺牲一定的吞吐量;可开启内存碎片整理,会停顿用户线程。ParallelGC :(JDK8)新生代(Parallel Scavenge复制算法),老年代(Paraller Old标记整理算法)。G1垃圾收集器 :吞吐量高,可预测的停顿;整体基于标记-整理算法,从局部(两个Region)是基于复制算法;设置了新生代大小相当于放弃了G1为我们做的自动调优。G1官方的建议——实时数据占用了超过半数的堆空间;对象分配率或“晋升”的速度变化明显;期望消除耗时较长的GC或停顿(超过0.5——1秒)。ZGC :着色指针(在对象的引用上标注了对象的信息),读屏障(把指针更新为有效地址再返回,也就是,永远只有单个对象读取时有概率被减速),Stop-The-World 只会在根对象扫描阶段发生,所以GC暂停时间并不会随着堆和存活对象的数量而增加。TB 级别的堆内存管理;最大 GC Pause 不高于 10ms;最大的吞吐率(Throughput)损耗不高于 15%。ParallelGC 吞吐量优先,后台运算而不需要太多交互的任务。CMS 响应速度优先,集中在互联网站或B/S系统服务端上的Java应用。G1 响应速度优先,面向服务端应用,将来替换CMS。{lamp/}内存划分为 JVM内存划分为堆内存和非堆内存,堆内存分为年轻代、老年代,非堆内存就一个永久代。在JDK1.8版本废弃了永久代,替代的是元空间(MetaSpace),元空间与永久代上类似,都是方法区的实现,他们最大区别是元空间并不在JVM中,而是使用本地内存。{lamp/}Full GC条件 a.发生minor gc之前会判断老年代最大可用连续空间是否大于新生代的所有对象总空间,如果大于直接发生minor gc,如果小于发生full gc。b.老年代空间不足时,创建一个大对象时Ended放不下,会直接保存到老年代中,如果老年代空间不足,就会触发full gc。c.显示调用System.gc()方法,可能会发生full gc。{lamp/}引用类型 强引用 :永远不会回收软引用SoftReference :内存不足时才会回收该对象。比如网页缓存、图片缓存等。弱引用WeakReference :每次垃圾回收。虚引用PhantomReference :虚引用必须和引用队列 (ReferenceQueue)联合使用,主要用来跟踪对象被垃圾回收器回收的活动。假如有一个应用需要读取大量的本地图片,如果每次读取图片都从硬盘读取,则会严重影响性能,但是如果全部加载到内存当中,又有可能造成内存溢出,此时使用软引用可以解决这个问题。
JAVA垃圾回收 垃圾回收算法 标记-清除算法 :产生不连续的内存碎片,为较大对象分配内存时无法找到足够连续的内存,不得不提前触发垃圾收集动作。CMS垃圾回收器。标记-整理算法 :存活的对象向一端移动,存活率高时,效率远高于复制算法。G1、ParallelGC(Paraller Old)。复制算法 :Eden、s0、s1,比例是8:1:1,10%被浪费,JDK8,ParallelGC(Parallel Scavenge)。分代收集算法 。{lamp/}垃圾回收器 CMS收集器 :发标记、并发清除、内存碎片、最短回收停顿时间为目标,与用户线程可以并发执行,牺牲一定的吞吐量;可开启内存碎片整理,会停顿用户线程。ParallelGC :(JDK8)新生代(Parallel Scavenge复制算法),老年代(Paraller Old标记整理算法)。G1垃圾收集器 :吞吐量高,可预测的停顿;整体基于标记-整理算法,从局部(两个Region)是基于复制算法;设置了新生代大小相当于放弃了G1为我们做的自动调优。G1官方的建议——实时数据占用了超过半数的堆空间;对象分配率或“晋升”的速度变化明显;期望消除耗时较长的GC或停顿(超过0.5——1秒)。ZGC :着色指针(在对象的引用上标注了对象的信息),读屏障(把指针更新为有效地址再返回,也就是,永远只有单个对象读取时有概率被减速),Stop-The-World 只会在根对象扫描阶段发生,所以GC暂停时间并不会随着堆和存活对象的数量而增加。TB 级别的堆内存管理;最大 GC Pause 不高于 10ms;最大的吞吐率(Throughput)损耗不高于 15%。ParallelGC 吞吐量优先,后台运算而不需要太多交互的任务。CMS 响应速度优先,集中在互联网站或B/S系统服务端上的Java应用。G1 响应速度优先,面向服务端应用,将来替换CMS。{lamp/}内存划分为 JVM内存划分为堆内存和非堆内存,堆内存分为年轻代、老年代,非堆内存就一个永久代。在JDK1.8版本废弃了永久代,替代的是元空间(MetaSpace),元空间与永久代上类似,都是方法区的实现,他们最大区别是元空间并不在JVM中,而是使用本地内存。{lamp/}Full GC条件 a.发生minor gc之前会判断老年代最大可用连续空间是否大于新生代的所有对象总空间,如果大于直接发生minor gc,如果小于发生full gc。b.老年代空间不足时,创建一个大对象时Ended放不下,会直接保存到老年代中,如果老年代空间不足,就会触发full gc。c.显示调用System.gc()方法,可能会发生full gc。{lamp/}引用类型 强引用 :永远不会回收软引用SoftReference :内存不足时才会回收该对象。比如网页缓存、图片缓存等。弱引用WeakReference :每次垃圾回收。虚引用PhantomReference :虚引用必须和引用队列 (ReferenceQueue)联合使用,主要用来跟踪对象被垃圾回收器回收的活动。假如有一个应用需要读取大量的本地图片,如果每次读取图片都从硬盘读取,则会严重影响性能,但是如果全部加载到内存当中,又有可能造成内存溢出,此时使用软引用可以解决这个问题。 -
![Hadoop各版本汇总]() Hadoop各版本汇总 Hadoop1.0 NameNode节点有且只有一个,虽然可以通过SecondaryNameNode进行主节点数据备份,但是存在延时情况,假如主节点挂掉,这时部分数据还未同步到SecondaryNameNode节点上,就会存在资源数据的缺失。因为NameNode是存储着DataNode节点等元数据信息。对于MapReduce,也是一个简单的主从结构,是有一个主JobTracker和多个从的TaskTracker组成,而且在hadoop1.0中JobTracker任务繁重。{lamp/}Hadoop2.0 增加了HDFS Federation(联邦)水平扩展,支持多个namenode同时运行,每一个namenode分管一批目录,然后共享所有datanode的存储资源,从而解决1.0当中单个namenode节点内存受限问题。HDFS的Federation,多个namenode(多个namespace),互相独立,互相协调,各自分工管理自己的区域,并不能解决单点故障问题,配合HA,每个namenode部署一个备机。增加了HDFS HA机制,解决了1.0中的单点故障问题,只支持两个节点,3.0实现了一主多从。增加了YARN框架,针对1.0中主JobTracker压力太大的不足,把JobTracker资源分配和作业控制分开,利用Resource Manager在namenode上进行资源管理调度,利用ApplicationMaster进行任务管理和任务监控。由NodeManager替代TaskTracker进行具体任务的执行,因此MapReduce2.0只是一个计算框架。对比1.0中相关资源的调用全部给Yarn框架管理。{lamp/}Hadoop3.0 Javaj运行环境升级为1.8,对之前低版本的Java不在支持。HDFS3.0支持数据的擦除编码,调高存储空间的使用率。一些默认端口的改变。增加一些MapReduce的调优。支持 2 个以上的 NameNode,例如,通过配置三个 NameNode 和五个 JournalNode,集群能够容忍两个节点而不是一个节点的故障。https://hadoop.apache.org/docs/r3.0.0
Hadoop各版本汇总 Hadoop1.0 NameNode节点有且只有一个,虽然可以通过SecondaryNameNode进行主节点数据备份,但是存在延时情况,假如主节点挂掉,这时部分数据还未同步到SecondaryNameNode节点上,就会存在资源数据的缺失。因为NameNode是存储着DataNode节点等元数据信息。对于MapReduce,也是一个简单的主从结构,是有一个主JobTracker和多个从的TaskTracker组成,而且在hadoop1.0中JobTracker任务繁重。{lamp/}Hadoop2.0 增加了HDFS Federation(联邦)水平扩展,支持多个namenode同时运行,每一个namenode分管一批目录,然后共享所有datanode的存储资源,从而解决1.0当中单个namenode节点内存受限问题。HDFS的Federation,多个namenode(多个namespace),互相独立,互相协调,各自分工管理自己的区域,并不能解决单点故障问题,配合HA,每个namenode部署一个备机。增加了HDFS HA机制,解决了1.0中的单点故障问题,只支持两个节点,3.0实现了一主多从。增加了YARN框架,针对1.0中主JobTracker压力太大的不足,把JobTracker资源分配和作业控制分开,利用Resource Manager在namenode上进行资源管理调度,利用ApplicationMaster进行任务管理和任务监控。由NodeManager替代TaskTracker进行具体任务的执行,因此MapReduce2.0只是一个计算框架。对比1.0中相关资源的调用全部给Yarn框架管理。{lamp/}Hadoop3.0 Javaj运行环境升级为1.8,对之前低版本的Java不在支持。HDFS3.0支持数据的擦除编码,调高存储空间的使用率。一些默认端口的改变。增加一些MapReduce的调优。支持 2 个以上的 NameNode,例如,通过配置三个 NameNode 和五个 JournalNode,集群能够容忍两个节点而不是一个节点的故障。https://hadoop.apache.org/docs/r3.0.0 -
![Spark学习笔记]() Spark学习笔记 Spark Streaming KafkaUtils.createStream:PUSH,Kafka高级API,数据漏处理或者多处理状况,主题分区与RDD的分区不相关,可开启WAL(数据复制两次)。KafkaUtils.createDirectStream:PULL,Kafka低级API,Kafka和RDD分区之间有一对一的映射关系,不会更新Zookeeper中的偏移量。{lamp/}内存管理 spark on yarn (yarn-cluster)Resource Manager接收到申请后在集群中选择一个Node Manager分配Container,并在Container中启动ApplicationMaster进程,在ApplicationMaster中初始化SparkContext,生成一系列task,ApplicationMaster向Resource Manager申请资源后通知Node Manager在获得的Container中启动Excutor进程,SparkContext分配task给Excutor,Excutor发送运行状态给Driver。一个Container对应一个JVM进程,也就是一个executor,所以JVM的Heap Size取决于spark.executor.memory。堆内存90%以上作为安全空间,如果内存大,可以调高95%。缓存空间是60%(Heep 90%60%)(safetyFraction 和 memoryFraction) ,会负责存储 Persist、Unroll 以及 Broadcast 的数据。Unroll序列化空间是20%(Heep 90%60%*20%)。shuffle空间的安全比例是80%,spark.shuffle.memeoryFraction 0.2(Heep 80% 20%)。Spark1.6之后 联合内存 加入Heap 4G预留内存(Reserved Memory):系统预留内存,会用来存储Spark内部对象。默认是300M,Java Heap大小至少为*1.5=450M。用户内存(User Memory):主要用于存储 RDD 转换操作所需要的数据,例如 RDD 依赖等信息。(Heap-300M)*25%=949M,每个 Executor 分配 1G 的数据就会OOM。Spark Memory, (Heap-300M)*75%,各50%,动态占用机制。Execution 内存:主要用于存放 Shuffle、Join、Sort、Aggregation 等计算过程中的临时数据。Storage 内存:主要用于存储 spark 的 cache 数据,例如RDD的缓存、unroll数据。Storage占用对方内存可能被淘汰,如果没有再磁盘存储会丢失(storage_level ),Execution占用对方内存只能等释放。先借用,再溢写到磁盘,内存优先。启用静态内存管理的方式是:spark.memory.useLegacyMode true{lamp/}RDD有多少分区就有多少task,因为一个task只能处理一个partition上的数据。Spark算子分为transform、action,只有action算子才触发计算(延迟计算)如:countbykey、reduce、count、take(n)、foreach、collect。一个action算子提交一个job、一个job包含一个或者多个stage、stage是根据RDD宽依赖(一个RDD分到两个不同的子RDD)、窄依赖(一个子RDD可以依赖多个父RDD)划分的。Excuotor(包含一个或者多个task,每个task一个虚拟core),Excuotor、task数量可以在submit中设置。总task数量一般设置成总core数的2-3倍,因为有的task可能先执行完。map一条记录变一条记录,function函数返回Object;faltmap一条记录变多条记录,function函数返回Iterable<Object>迭代器。join操作时,可以将reduce join转换成map join,并广播大变量。{lamp/}SHUFFLE 有hashshuffle、sortshuffle、钨丝shuffle,后者会进行排序,一个task一个文件,钨丝shuffle效果跟sort差不多, 使用了自己实现的一套内存管理机制,性能上有很大的提升。hashshuffle,map端写文件时每个task都会创建下一个stage总task数量的文件,可以设置合并,这样,每个excutor中的task就会公用一批文件,先往内存缓存写,再溢出到磁盘,调整大一些可以减少io次数,reduce端拉取文件时有buffer缓冲区,每次都只能拉取与buffer缓冲相同大小的数据。{lamp/}调优 Spark优化还包括,设置kyro序列化方式 ,性能更高、调整RDD持久化内存比例、调整shuffle时reduce端拉取数据重试次数,等待时长(因为在JVM full gc时是stop the world,多尝试几次)、数据本地化等待时长。
Spark学习笔记 Spark Streaming KafkaUtils.createStream:PUSH,Kafka高级API,数据漏处理或者多处理状况,主题分区与RDD的分区不相关,可开启WAL(数据复制两次)。KafkaUtils.createDirectStream:PULL,Kafka低级API,Kafka和RDD分区之间有一对一的映射关系,不会更新Zookeeper中的偏移量。{lamp/}内存管理 spark on yarn (yarn-cluster)Resource Manager接收到申请后在集群中选择一个Node Manager分配Container,并在Container中启动ApplicationMaster进程,在ApplicationMaster中初始化SparkContext,生成一系列task,ApplicationMaster向Resource Manager申请资源后通知Node Manager在获得的Container中启动Excutor进程,SparkContext分配task给Excutor,Excutor发送运行状态给Driver。一个Container对应一个JVM进程,也就是一个executor,所以JVM的Heap Size取决于spark.executor.memory。堆内存90%以上作为安全空间,如果内存大,可以调高95%。缓存空间是60%(Heep 90%60%)(safetyFraction 和 memoryFraction) ,会负责存储 Persist、Unroll 以及 Broadcast 的数据。Unroll序列化空间是20%(Heep 90%60%*20%)。shuffle空间的安全比例是80%,spark.shuffle.memeoryFraction 0.2(Heep 80% 20%)。Spark1.6之后 联合内存 加入Heap 4G预留内存(Reserved Memory):系统预留内存,会用来存储Spark内部对象。默认是300M,Java Heap大小至少为*1.5=450M。用户内存(User Memory):主要用于存储 RDD 转换操作所需要的数据,例如 RDD 依赖等信息。(Heap-300M)*25%=949M,每个 Executor 分配 1G 的数据就会OOM。Spark Memory, (Heap-300M)*75%,各50%,动态占用机制。Execution 内存:主要用于存放 Shuffle、Join、Sort、Aggregation 等计算过程中的临时数据。Storage 内存:主要用于存储 spark 的 cache 数据,例如RDD的缓存、unroll数据。Storage占用对方内存可能被淘汰,如果没有再磁盘存储会丢失(storage_level ),Execution占用对方内存只能等释放。先借用,再溢写到磁盘,内存优先。启用静态内存管理的方式是:spark.memory.useLegacyMode true{lamp/}RDD有多少分区就有多少task,因为一个task只能处理一个partition上的数据。Spark算子分为transform、action,只有action算子才触发计算(延迟计算)如:countbykey、reduce、count、take(n)、foreach、collect。一个action算子提交一个job、一个job包含一个或者多个stage、stage是根据RDD宽依赖(一个RDD分到两个不同的子RDD)、窄依赖(一个子RDD可以依赖多个父RDD)划分的。Excuotor(包含一个或者多个task,每个task一个虚拟core),Excuotor、task数量可以在submit中设置。总task数量一般设置成总core数的2-3倍,因为有的task可能先执行完。map一条记录变一条记录,function函数返回Object;faltmap一条记录变多条记录,function函数返回Iterable<Object>迭代器。join操作时,可以将reduce join转换成map join,并广播大变量。{lamp/}SHUFFLE 有hashshuffle、sortshuffle、钨丝shuffle,后者会进行排序,一个task一个文件,钨丝shuffle效果跟sort差不多, 使用了自己实现的一套内存管理机制,性能上有很大的提升。hashshuffle,map端写文件时每个task都会创建下一个stage总task数量的文件,可以设置合并,这样,每个excutor中的task就会公用一批文件,先往内存缓存写,再溢出到磁盘,调整大一些可以减少io次数,reduce端拉取文件时有buffer缓冲区,每次都只能拉取与buffer缓冲相同大小的数据。{lamp/}调优 Spark优化还包括,设置kyro序列化方式 ,性能更高、调整RDD持久化内存比例、调整shuffle时reduce端拉取数据重试次数,等待时长(因为在JVM full gc时是stop the world,多尝试几次)、数据本地化等待时长。 -
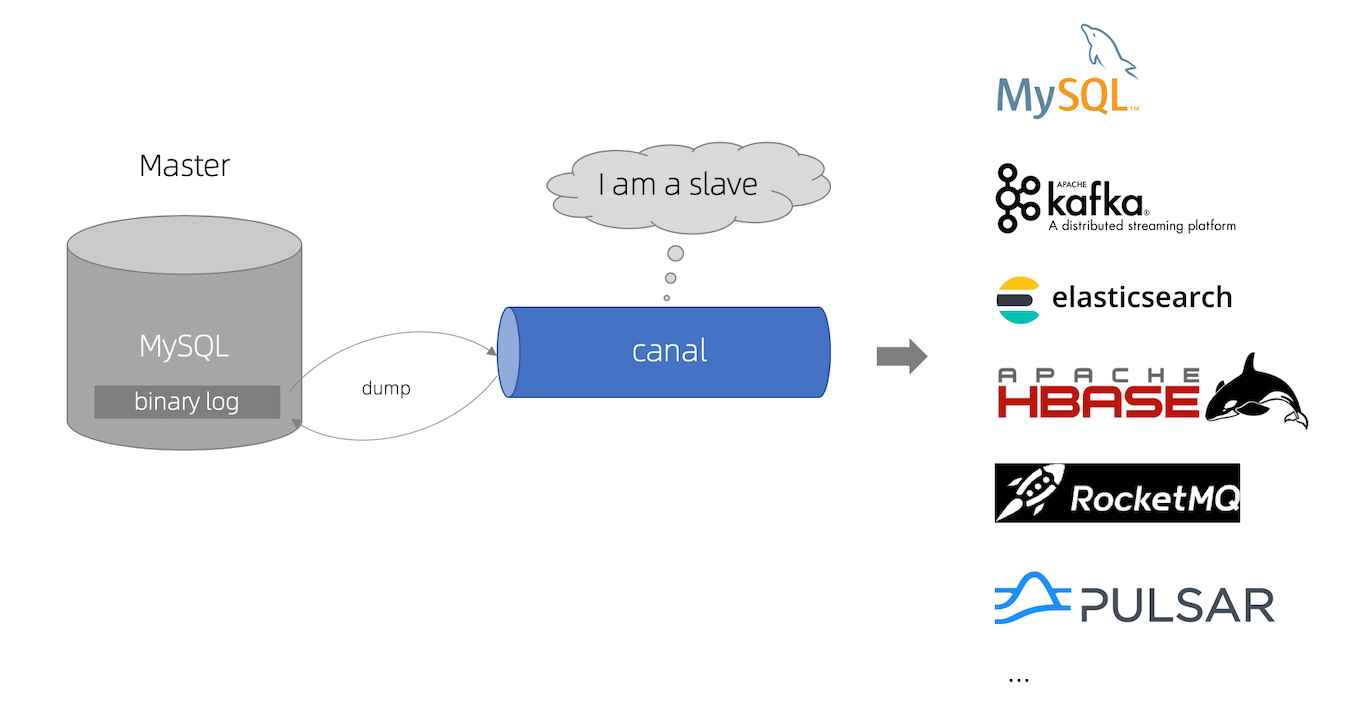
![数据同步工具DataX、Sqoop和Canal]()
-
![Kafka、RocketMQ消息队列总结]() Kafka、RocketMQ消息队列总结 Kafka 同一个partition内的消息只能被同一个组中的一个consumer消费,当消费者数量多于partition的数量时,多余的消费者空闲。每个partition为一个目录,partiton命名规则为topic名称+有序序号,每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中,默认保留7天的数据。Kafka支持以Partition为单位对Message进行冗余备份,每个Replication集合中的Partition都会选出一个唯一的Leader,所有的读写请求都由Leader处理,其他Replicas从Leader处把数据更新同步到本地。Offset:消息在Partition中的编号,编号顺序不跨Partition。消费失败不支持重试,组与组之间的消息是否被消费是相互隔离互不影响的。kafka可以横向扩展,堆积能力强,当你需要进行大量数据的持久化。kafka的ack机制:在kafka发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够被收到。重复消费(已经消费了数据,但是offset没提交),每次消费时更新每个topic+partition位置的offset在内存中,多台服务器集群,offset要做去重处理。消息丢失,producer同步模式(ack)、异步模式(buffer满了不清理),consumer自己手动维护偏移量。{lamp/}RocketMQ Topic分片再切分为若干等分,其中的一份就是一个Queue。一个broker对应一组消息文件commitLog,所有topic的消息都存在commitLog中,consumerqueue保存的是消息在commitLog中的地址 。broker主从(单Master、多Master、Master-Slave(异步复制)、Master-Slave(同步双写))。consumer第一次默认从master节点拉取消息,未消费的数据量占物理内存的比例,当超过40%时,会返回建议的拉取节点id。RocketMQ不保证消息不重复。消息丢失(在各个层都可能发生),producer同步(send不报错)异步(重写回调方法),生产者返回消息状态,开启重试消费。顺序消息,必须Producer单线程顺序发送,且发送到同一个队列,一个queue对应一个consumer,Broker重启,由于队列总数发生变化,哈希取模后定位的队列会变化,产生短暂的消息顺序不一致。RocketMQ可以严格的保证消息有序。但这个顺序,不是全局顺序,只是分区(queue)顺序。要全局顺序只能一个分区,kafka是放同一个topic。一个Queue最多只能分配给一个Consumer。Queue是Topic在一个Broker上的分片等分为指定份数后的其中一份,是负载均衡过程中资源分配的基本单元。{lamp/}消费并行度 Kafka消费并行度和分区数一致;RocketMQ消费并行度分两种情况,顺序消费方式并行度同Kafka完全一致,乱序方式并行度取决于Consumer的线程数,如Topic配置10个队列,10台机器消费,每台机器100个线程,那么并行度为1000。
Kafka、RocketMQ消息队列总结 Kafka 同一个partition内的消息只能被同一个组中的一个consumer消费,当消费者数量多于partition的数量时,多余的消费者空闲。每个partition为一个目录,partiton命名规则为topic名称+有序序号,每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中,默认保留7天的数据。Kafka支持以Partition为单位对Message进行冗余备份,每个Replication集合中的Partition都会选出一个唯一的Leader,所有的读写请求都由Leader处理,其他Replicas从Leader处把数据更新同步到本地。Offset:消息在Partition中的编号,编号顺序不跨Partition。消费失败不支持重试,组与组之间的消息是否被消费是相互隔离互不影响的。kafka可以横向扩展,堆积能力强,当你需要进行大量数据的持久化。kafka的ack机制:在kafka发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够被收到。重复消费(已经消费了数据,但是offset没提交),每次消费时更新每个topic+partition位置的offset在内存中,多台服务器集群,offset要做去重处理。消息丢失,producer同步模式(ack)、异步模式(buffer满了不清理),consumer自己手动维护偏移量。{lamp/}RocketMQ Topic分片再切分为若干等分,其中的一份就是一个Queue。一个broker对应一组消息文件commitLog,所有topic的消息都存在commitLog中,consumerqueue保存的是消息在commitLog中的地址 。broker主从(单Master、多Master、Master-Slave(异步复制)、Master-Slave(同步双写))。consumer第一次默认从master节点拉取消息,未消费的数据量占物理内存的比例,当超过40%时,会返回建议的拉取节点id。RocketMQ不保证消息不重复。消息丢失(在各个层都可能发生),producer同步(send不报错)异步(重写回调方法),生产者返回消息状态,开启重试消费。顺序消息,必须Producer单线程顺序发送,且发送到同一个队列,一个queue对应一个consumer,Broker重启,由于队列总数发生变化,哈希取模后定位的队列会变化,产生短暂的消息顺序不一致。RocketMQ可以严格的保证消息有序。但这个顺序,不是全局顺序,只是分区(queue)顺序。要全局顺序只能一个分区,kafka是放同一个topic。一个Queue最多只能分配给一个Consumer。Queue是Topic在一个Broker上的分片等分为指定份数后的其中一份,是负载均衡过程中资源分配的基本单元。{lamp/}消费并行度 Kafka消费并行度和分区数一致;RocketMQ消费并行度分两种情况,顺序消费方式并行度同Kafka完全一致,乱序方式并行度取决于Consumer的线程数,如Topic配置10个队列,10台机器消费,每台机器100个线程,那么并行度为1000。