搜索到
10
篇与
大数据
的结果
返回首页
-
![Flink 任务执行流程源码解析]() Flink 任务执行流程源码解析 用户提交Flink任务时,通过先后调用transform()——>doTransform()——>addOperator()方法,将map、flatMap、filter、process等算子添加到List<Transformation<?>> transformations集合中。在执行execute()方法时,会使用StreamGraphGenerator的generate()方法构建流拓扑StreamGraph(即Pipeline),数据结构属于有向无环图。在StreamGraph中,StreamNode用于记录算子信息,而StreamEdge则用于记录数据交换方式,包括以下几种Partitioner:{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}Partitioner类都是StreamPartitioner类的子类,它们通过实现isPointwise()方法来确定自身的类型。一种是ALL_TO_ALL,另一个种是POINTWISE。/** * A distribution pattern determines, which sub tasks of a producing task are connected to which * consuming sub tasks. * * <p>It affects how {@link ExecutionVertex} and {@link IntermediateResultPartition} are connected * in {@link EdgeManagerBuildUtil} */ public enum DistributionPattern { /** Each producing sub task is connected to each sub task of the consuming task. */ ALL_TO_ALL, /** Each producing sub task is connected to one or more subtask(s) of the consuming task. */ POINTWISE }ALL_TO_ALL意味着上游的每个subtask需要与下游的每个subtask建立连接。{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}POINTWISE则是上游的每个subtask和下游的一个或多个subtask连接。{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}StreamGraph构建完成后,,会通过 PipelineExecutorUtils.getJobGraph()构建JobGraph,具体流程是:——>PipelineExecutorUtils.getJobGraph() ——>FlinkPipelineTranslationUtil.getJobGraph() ——>StreamGraphTranslator.translateToJobGraph() ——>StreamGraph.getJobGraph() ——>StreamingJobGraphGenerator.createJobGraph()JobGraph是优化后的StreamGraph,如果相连的算子支持chaining,合并到一个StreamNode,chaining在StreamingJobGraphGenerator的setChaining()方法中实现:/** * Sets up task chains from the source {@link StreamNode} instances. * * <p>This will recursively create all {@link JobVertex} instances. */ private void setChaining(Map<Integer, byte[]> hashes, List<Map<Integer, byte[]>> legacyHashes) { // we separate out the sources that run as inputs to another operator (chained inputs) // from the sources that needs to run as the main (head) operator. final Map<Integer, OperatorChainInfo> chainEntryPoints = buildChainedInputsAndGetHeadInputs(hashes, legacyHashes); final Collection<OperatorChainInfo> initialEntryPoints = chainEntryPoints.entrySet().stream() .sorted(Comparator.comparing(Map.Entry::getKey)) .map(Map.Entry::getValue) .collect(Collectors.toList()); // iterate over a copy of the values, because this map gets concurrently modified for (OperatorChainInfo info : initialEntryPoints) { createChain( info.getStartNodeId(), 1, // operators start at position 1 because 0 is for chained source inputs info, chainEntryPoints); } }将符合chaining条件的,合并到一个StreamNode条件如下:1. 下游节点输入边只有一个 2. 与下游属于同一个SlotSharingGroup 3. 数据分发策略Forward 4. 流数据交换模式不是批量模式 5. 上下游并行度相等 6. StreamGraph中chaining为true streamGraph 是可以 chain的 7. 算子是否可以链化areOperatorsChainable代码如下:public static boolean isChainable(StreamEdge edge, StreamGraph streamGraph) { StreamNode downStreamVertex = streamGraph.getTargetVertex(edge); return downStreamVertex.getInEdges().size() == 1 && isChainableInput(edge, streamGraph); } private static boolean isChainableInput(StreamEdge edge, StreamGraph streamGraph) { StreamNode upStreamVertex = streamGraph.getSourceVertex(edge); StreamNode downStreamVertex = streamGraph.getTargetVertex(edge); if (!(upStreamVertex.isSameSlotSharingGroup(downStreamVertex) && areOperatorsChainable(upStreamVertex, downStreamVertex, streamGraph) && (edge.getPartitioner() instanceof ForwardPartitioner) && edge.getExchangeMode() != StreamExchangeMode.BATCH && upStreamVertex.getParallelism() == downStreamVertex.getParallelism() && streamGraph.isChainingEnabled())) { return false; } ... ... 从Source节点开始,使用深度优先搜索(DFS)算法递归遍历有向无环图中的所有StreamNode节点。{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}待续 ... ...
Flink 任务执行流程源码解析 用户提交Flink任务时,通过先后调用transform()——>doTransform()——>addOperator()方法,将map、flatMap、filter、process等算子添加到List<Transformation<?>> transformations集合中。在执行execute()方法时,会使用StreamGraphGenerator的generate()方法构建流拓扑StreamGraph(即Pipeline),数据结构属于有向无环图。在StreamGraph中,StreamNode用于记录算子信息,而StreamEdge则用于记录数据交换方式,包括以下几种Partitioner:{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}Partitioner类都是StreamPartitioner类的子类,它们通过实现isPointwise()方法来确定自身的类型。一种是ALL_TO_ALL,另一个种是POINTWISE。/** * A distribution pattern determines, which sub tasks of a producing task are connected to which * consuming sub tasks. * * <p>It affects how {@link ExecutionVertex} and {@link IntermediateResultPartition} are connected * in {@link EdgeManagerBuildUtil} */ public enum DistributionPattern { /** Each producing sub task is connected to each sub task of the consuming task. */ ALL_TO_ALL, /** Each producing sub task is connected to one or more subtask(s) of the consuming task. */ POINTWISE }ALL_TO_ALL意味着上游的每个subtask需要与下游的每个subtask建立连接。{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}POINTWISE则是上游的每个subtask和下游的一个或多个subtask连接。{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}StreamGraph构建完成后,,会通过 PipelineExecutorUtils.getJobGraph()构建JobGraph,具体流程是:——>PipelineExecutorUtils.getJobGraph() ——>FlinkPipelineTranslationUtil.getJobGraph() ——>StreamGraphTranslator.translateToJobGraph() ——>StreamGraph.getJobGraph() ——>StreamingJobGraphGenerator.createJobGraph()JobGraph是优化后的StreamGraph,如果相连的算子支持chaining,合并到一个StreamNode,chaining在StreamingJobGraphGenerator的setChaining()方法中实现:/** * Sets up task chains from the source {@link StreamNode} instances. * * <p>This will recursively create all {@link JobVertex} instances. */ private void setChaining(Map<Integer, byte[]> hashes, List<Map<Integer, byte[]>> legacyHashes) { // we separate out the sources that run as inputs to another operator (chained inputs) // from the sources that needs to run as the main (head) operator. final Map<Integer, OperatorChainInfo> chainEntryPoints = buildChainedInputsAndGetHeadInputs(hashes, legacyHashes); final Collection<OperatorChainInfo> initialEntryPoints = chainEntryPoints.entrySet().stream() .sorted(Comparator.comparing(Map.Entry::getKey)) .map(Map.Entry::getValue) .collect(Collectors.toList()); // iterate over a copy of the values, because this map gets concurrently modified for (OperatorChainInfo info : initialEntryPoints) { createChain( info.getStartNodeId(), 1, // operators start at position 1 because 0 is for chained source inputs info, chainEntryPoints); } }将符合chaining条件的,合并到一个StreamNode条件如下:1. 下游节点输入边只有一个 2. 与下游属于同一个SlotSharingGroup 3. 数据分发策略Forward 4. 流数据交换模式不是批量模式 5. 上下游并行度相等 6. StreamGraph中chaining为true streamGraph 是可以 chain的 7. 算子是否可以链化areOperatorsChainable代码如下:public static boolean isChainable(StreamEdge edge, StreamGraph streamGraph) { StreamNode downStreamVertex = streamGraph.getTargetVertex(edge); return downStreamVertex.getInEdges().size() == 1 && isChainableInput(edge, streamGraph); } private static boolean isChainableInput(StreamEdge edge, StreamGraph streamGraph) { StreamNode upStreamVertex = streamGraph.getSourceVertex(edge); StreamNode downStreamVertex = streamGraph.getTargetVertex(edge); if (!(upStreamVertex.isSameSlotSharingGroup(downStreamVertex) && areOperatorsChainable(upStreamVertex, downStreamVertex, streamGraph) && (edge.getPartitioner() instanceof ForwardPartitioner) && edge.getExchangeMode() != StreamExchangeMode.BATCH && upStreamVertex.getParallelism() == downStreamVertex.getParallelism() && streamGraph.isChainingEnabled())) { return false; } ... ... 从Source节点开始,使用深度优先搜索(DFS)算法递归遍历有向无环图中的所有StreamNode节点。{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}{dotted startColor="#b3b2b2" endColor="#b3b2b2"/}待续 ... ... -
![Flink实时计算问题记录与解决方案]() Flink实时计算问题记录与解决方案 当Flink任务的并行度大于Kafka分区数时,可能会导致部分并行度空闲,进而影响水位线(watermark)的生成。为了解决这个问题,可以通过设置withIdleness来进行调整:WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withIdleness(Duration.ofSeconds(60))对于withIdleness参数,应避免将下游任务设置得太小。原因在于,如果上游任务因故障停止,而其恢复所需时间超过了下游任务设置的withIdleness值,那么下游任务会将超时的分区标记为不再消费,导致数据丢失。为避免此问题,建议将分区数设置为不小于任务的并行度,并不设置withIdleness参数,这样可以有效防止潜在的数据丢失情况。{lamp/}kafkaSource指定时间戳消费时,必须为毫秒时间戳,Flink 1.14官网文档为秒,是错误的,指定后不会生效。setStartingOffsets(OffsetsInitializer.timestamp(1654703973000L)){lamp/}要实现Flink与Kafka的端到端一致性,需要确保Kafka的版本不低于2.5。要注意的是,Flink 1.14.2中flink-connector所包含的kafka-clients版本是2.4.X。because of a bug in the Kafka broker (KAFKA-9310). Please upgrade to Kafka 2.5+. If you are running with concurrent checkpoints, you also may want to try without them.Flink-Kafka端到端一致性需要设置TRANSACTIONAL_ID_CONFIG = "transactional.id",如果不设置,从checkpoint重启会报错:OutOfOrderSequenceException: The broker received an out of order sequence number。{lamp/}Flink CDC同步mysql时,需要把binlog配置成ROW模式,查看命令和配置方法如下:show variables like 'binlog_format%'; vi /etc/my.cnf binlog_format=row systemctl restart mariadb.service非ROW模式时会报以下错误:Caused by: org.apache.flink.table.api.ValidationException: The MySQL server is configured with binlog_format MIXED rather than ROW, which is required for this connector to work properly. Change the MySQL configuration to use a binlog_format=ROW and restart the connector.Flink 1.14.2版本使用CDC 2.2,需要编译CDC源码进行版本适配:1.pom文件中修改flink版本为1.14.2、scala版本为2.12.72.修改flink-table-planner-blink为flink-table-planner;flink-table-runtime-blink为flink-table-runtime3.flink-shaded-guava版本由30.1.1-jre-14.0修改为18.0-13.0修改完成后,会出现部分import报错的情况。需要根据新依赖版本中的路径和类进行相应的修改,例如,将创建TimestampFormat的代码修改为:TimestampFormat timestampOption = JsonFormatOptionsUtil.getTimestampFormat(formatOptions)。在编译过程中,首先需要使用install命令对父module进行安装。这样可以确保本地Maven仓库中包含各个子module的JAR包。对子module进行打包时,如Flink MySQL CDC,可以在子module的POM文件中修改打包方式,将所有依赖项都打包到一个JAR文件中,这样在工程中只需引入一个<dependency>即可。否则,会因为缺少某些依赖报错,如:Could not initialize class io.debezium.connector.mysql.MySqlConnectorConfig
Flink实时计算问题记录与解决方案 当Flink任务的并行度大于Kafka分区数时,可能会导致部分并行度空闲,进而影响水位线(watermark)的生成。为了解决这个问题,可以通过设置withIdleness来进行调整:WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withIdleness(Duration.ofSeconds(60))对于withIdleness参数,应避免将下游任务设置得太小。原因在于,如果上游任务因故障停止,而其恢复所需时间超过了下游任务设置的withIdleness值,那么下游任务会将超时的分区标记为不再消费,导致数据丢失。为避免此问题,建议将分区数设置为不小于任务的并行度,并不设置withIdleness参数,这样可以有效防止潜在的数据丢失情况。{lamp/}kafkaSource指定时间戳消费时,必须为毫秒时间戳,Flink 1.14官网文档为秒,是错误的,指定后不会生效。setStartingOffsets(OffsetsInitializer.timestamp(1654703973000L)){lamp/}要实现Flink与Kafka的端到端一致性,需要确保Kafka的版本不低于2.5。要注意的是,Flink 1.14.2中flink-connector所包含的kafka-clients版本是2.4.X。because of a bug in the Kafka broker (KAFKA-9310). Please upgrade to Kafka 2.5+. If you are running with concurrent checkpoints, you also may want to try without them.Flink-Kafka端到端一致性需要设置TRANSACTIONAL_ID_CONFIG = "transactional.id",如果不设置,从checkpoint重启会报错:OutOfOrderSequenceException: The broker received an out of order sequence number。{lamp/}Flink CDC同步mysql时,需要把binlog配置成ROW模式,查看命令和配置方法如下:show variables like 'binlog_format%'; vi /etc/my.cnf binlog_format=row systemctl restart mariadb.service非ROW模式时会报以下错误:Caused by: org.apache.flink.table.api.ValidationException: The MySQL server is configured with binlog_format MIXED rather than ROW, which is required for this connector to work properly. Change the MySQL configuration to use a binlog_format=ROW and restart the connector.Flink 1.14.2版本使用CDC 2.2,需要编译CDC源码进行版本适配:1.pom文件中修改flink版本为1.14.2、scala版本为2.12.72.修改flink-table-planner-blink为flink-table-planner;flink-table-runtime-blink为flink-table-runtime3.flink-shaded-guava版本由30.1.1-jre-14.0修改为18.0-13.0修改完成后,会出现部分import报错的情况。需要根据新依赖版本中的路径和类进行相应的修改,例如,将创建TimestampFormat的代码修改为:TimestampFormat timestampOption = JsonFormatOptionsUtil.getTimestampFormat(formatOptions)。在编译过程中,首先需要使用install命令对父module进行安装。这样可以确保本地Maven仓库中包含各个子module的JAR包。对子module进行打包时,如Flink MySQL CDC,可以在子module的POM文件中修改打包方式,将所有依赖项都打包到一个JAR文件中,这样在工程中只需引入一个<dependency>即可。否则,会因为缺少某些依赖报错,如:Could not initialize class io.debezium.connector.mysql.MySqlConnectorConfig -
![Hadoop各版本汇总]() Hadoop各版本汇总 Hadoop1.0 NameNode节点有且只有一个,虽然可以通过SecondaryNameNode进行主节点数据备份,但是存在延时情况,假如主节点挂掉,这时部分数据还未同步到SecondaryNameNode节点上,就会存在资源数据的缺失。因为NameNode是存储着DataNode节点等元数据信息。对于MapReduce,也是一个简单的主从结构,是有一个主JobTracker和多个从的TaskTracker组成,而且在hadoop1.0中JobTracker任务繁重。{lamp/}Hadoop2.0 增加了HDFS Federation(联邦)水平扩展,支持多个namenode同时运行,每一个namenode分管一批目录,然后共享所有datanode的存储资源,从而解决1.0当中单个namenode节点内存受限问题。HDFS的Federation,多个namenode(多个namespace),互相独立,互相协调,各自分工管理自己的区域,并不能解决单点故障问题,配合HA,每个namenode部署一个备机。增加了HDFS HA机制,解决了1.0中的单点故障问题,只支持两个节点,3.0实现了一主多从。增加了YARN框架,针对1.0中主JobTracker压力太大的不足,把JobTracker资源分配和作业控制分开,利用Resource Manager在namenode上进行资源管理调度,利用ApplicationMaster进行任务管理和任务监控。由NodeManager替代TaskTracker进行具体任务的执行,因此MapReduce2.0只是一个计算框架。对比1.0中相关资源的调用全部给Yarn框架管理。{lamp/}Hadoop3.0 Javaj运行环境升级为1.8,对之前低版本的Java不在支持。HDFS3.0支持数据的擦除编码,调高存储空间的使用率。一些默认端口的改变。增加一些MapReduce的调优。支持 2 个以上的 NameNode,例如,通过配置三个 NameNode 和五个 JournalNode,集群能够容忍两个节点而不是一个节点的故障。https://hadoop.apache.org/docs/r3.0.0
Hadoop各版本汇总 Hadoop1.0 NameNode节点有且只有一个,虽然可以通过SecondaryNameNode进行主节点数据备份,但是存在延时情况,假如主节点挂掉,这时部分数据还未同步到SecondaryNameNode节点上,就会存在资源数据的缺失。因为NameNode是存储着DataNode节点等元数据信息。对于MapReduce,也是一个简单的主从结构,是有一个主JobTracker和多个从的TaskTracker组成,而且在hadoop1.0中JobTracker任务繁重。{lamp/}Hadoop2.0 增加了HDFS Federation(联邦)水平扩展,支持多个namenode同时运行,每一个namenode分管一批目录,然后共享所有datanode的存储资源,从而解决1.0当中单个namenode节点内存受限问题。HDFS的Federation,多个namenode(多个namespace),互相独立,互相协调,各自分工管理自己的区域,并不能解决单点故障问题,配合HA,每个namenode部署一个备机。增加了HDFS HA机制,解决了1.0中的单点故障问题,只支持两个节点,3.0实现了一主多从。增加了YARN框架,针对1.0中主JobTracker压力太大的不足,把JobTracker资源分配和作业控制分开,利用Resource Manager在namenode上进行资源管理调度,利用ApplicationMaster进行任务管理和任务监控。由NodeManager替代TaskTracker进行具体任务的执行,因此MapReduce2.0只是一个计算框架。对比1.0中相关资源的调用全部给Yarn框架管理。{lamp/}Hadoop3.0 Javaj运行环境升级为1.8,对之前低版本的Java不在支持。HDFS3.0支持数据的擦除编码,调高存储空间的使用率。一些默认端口的改变。增加一些MapReduce的调优。支持 2 个以上的 NameNode,例如,通过配置三个 NameNode 和五个 JournalNode,集群能够容忍两个节点而不是一个节点的故障。https://hadoop.apache.org/docs/r3.0.0 -
![Spark学习笔记]() Spark学习笔记 Spark Streaming KafkaUtils.createStream:PUSH,Kafka高级API,数据漏处理或者多处理状况,主题分区与RDD的分区不相关,可开启WAL(数据复制两次)。KafkaUtils.createDirectStream:PULL,Kafka低级API,Kafka和RDD分区之间有一对一的映射关系,不会更新Zookeeper中的偏移量。{lamp/}内存管理 spark on yarn (yarn-cluster)Resource Manager接收到申请后在集群中选择一个Node Manager分配Container,并在Container中启动ApplicationMaster进程,在ApplicationMaster中初始化SparkContext,生成一系列task,ApplicationMaster向Resource Manager申请资源后通知Node Manager在获得的Container中启动Excutor进程,SparkContext分配task给Excutor,Excutor发送运行状态给Driver。一个Container对应一个JVM进程,也就是一个executor,所以JVM的Heap Size取决于spark.executor.memory。堆内存90%以上作为安全空间,如果内存大,可以调高95%。缓存空间是60%(Heep 90%60%)(safetyFraction 和 memoryFraction) ,会负责存储 Persist、Unroll 以及 Broadcast 的数据。Unroll序列化空间是20%(Heep 90%60%*20%)。shuffle空间的安全比例是80%,spark.shuffle.memeoryFraction 0.2(Heep 80% 20%)。Spark1.6之后 联合内存 加入Heap 4G预留内存(Reserved Memory):系统预留内存,会用来存储Spark内部对象。默认是300M,Java Heap大小至少为*1.5=450M。用户内存(User Memory):主要用于存储 RDD 转换操作所需要的数据,例如 RDD 依赖等信息。(Heap-300M)*25%=949M,每个 Executor 分配 1G 的数据就会OOM。Spark Memory, (Heap-300M)*75%,各50%,动态占用机制。Execution 内存:主要用于存放 Shuffle、Join、Sort、Aggregation 等计算过程中的临时数据。Storage 内存:主要用于存储 spark 的 cache 数据,例如RDD的缓存、unroll数据。Storage占用对方内存可能被淘汰,如果没有再磁盘存储会丢失(storage_level ),Execution占用对方内存只能等释放。先借用,再溢写到磁盘,内存优先。启用静态内存管理的方式是:spark.memory.useLegacyMode true{lamp/}RDD有多少分区就有多少task,因为一个task只能处理一个partition上的数据。Spark算子分为transform、action,只有action算子才触发计算(延迟计算)如:countbykey、reduce、count、take(n)、foreach、collect。一个action算子提交一个job、一个job包含一个或者多个stage、stage是根据RDD宽依赖(一个RDD分到两个不同的子RDD)、窄依赖(一个子RDD可以依赖多个父RDD)划分的。Excuotor(包含一个或者多个task,每个task一个虚拟core),Excuotor、task数量可以在submit中设置。总task数量一般设置成总core数的2-3倍,因为有的task可能先执行完。map一条记录变一条记录,function函数返回Object;faltmap一条记录变多条记录,function函数返回Iterable<Object>迭代器。join操作时,可以将reduce join转换成map join,并广播大变量。{lamp/}SHUFFLE 有hashshuffle、sortshuffle、钨丝shuffle,后者会进行排序,一个task一个文件,钨丝shuffle效果跟sort差不多, 使用了自己实现的一套内存管理机制,性能上有很大的提升。hashshuffle,map端写文件时每个task都会创建下一个stage总task数量的文件,可以设置合并,这样,每个excutor中的task就会公用一批文件,先往内存缓存写,再溢出到磁盘,调整大一些可以减少io次数,reduce端拉取文件时有buffer缓冲区,每次都只能拉取与buffer缓冲相同大小的数据。{lamp/}调优 Spark优化还包括,设置kyro序列化方式 ,性能更高、调整RDD持久化内存比例、调整shuffle时reduce端拉取数据重试次数,等待时长(因为在JVM full gc时是stop the world,多尝试几次)、数据本地化等待时长。
Spark学习笔记 Spark Streaming KafkaUtils.createStream:PUSH,Kafka高级API,数据漏处理或者多处理状况,主题分区与RDD的分区不相关,可开启WAL(数据复制两次)。KafkaUtils.createDirectStream:PULL,Kafka低级API,Kafka和RDD分区之间有一对一的映射关系,不会更新Zookeeper中的偏移量。{lamp/}内存管理 spark on yarn (yarn-cluster)Resource Manager接收到申请后在集群中选择一个Node Manager分配Container,并在Container中启动ApplicationMaster进程,在ApplicationMaster中初始化SparkContext,生成一系列task,ApplicationMaster向Resource Manager申请资源后通知Node Manager在获得的Container中启动Excutor进程,SparkContext分配task给Excutor,Excutor发送运行状态给Driver。一个Container对应一个JVM进程,也就是一个executor,所以JVM的Heap Size取决于spark.executor.memory。堆内存90%以上作为安全空间,如果内存大,可以调高95%。缓存空间是60%(Heep 90%60%)(safetyFraction 和 memoryFraction) ,会负责存储 Persist、Unroll 以及 Broadcast 的数据。Unroll序列化空间是20%(Heep 90%60%*20%)。shuffle空间的安全比例是80%,spark.shuffle.memeoryFraction 0.2(Heep 80% 20%)。Spark1.6之后 联合内存 加入Heap 4G预留内存(Reserved Memory):系统预留内存,会用来存储Spark内部对象。默认是300M,Java Heap大小至少为*1.5=450M。用户内存(User Memory):主要用于存储 RDD 转换操作所需要的数据,例如 RDD 依赖等信息。(Heap-300M)*25%=949M,每个 Executor 分配 1G 的数据就会OOM。Spark Memory, (Heap-300M)*75%,各50%,动态占用机制。Execution 内存:主要用于存放 Shuffle、Join、Sort、Aggregation 等计算过程中的临时数据。Storage 内存:主要用于存储 spark 的 cache 数据,例如RDD的缓存、unroll数据。Storage占用对方内存可能被淘汰,如果没有再磁盘存储会丢失(storage_level ),Execution占用对方内存只能等释放。先借用,再溢写到磁盘,内存优先。启用静态内存管理的方式是:spark.memory.useLegacyMode true{lamp/}RDD有多少分区就有多少task,因为一个task只能处理一个partition上的数据。Spark算子分为transform、action,只有action算子才触发计算(延迟计算)如:countbykey、reduce、count、take(n)、foreach、collect。一个action算子提交一个job、一个job包含一个或者多个stage、stage是根据RDD宽依赖(一个RDD分到两个不同的子RDD)、窄依赖(一个子RDD可以依赖多个父RDD)划分的。Excuotor(包含一个或者多个task,每个task一个虚拟core),Excuotor、task数量可以在submit中设置。总task数量一般设置成总core数的2-3倍,因为有的task可能先执行完。map一条记录变一条记录,function函数返回Object;faltmap一条记录变多条记录,function函数返回Iterable<Object>迭代器。join操作时,可以将reduce join转换成map join,并广播大变量。{lamp/}SHUFFLE 有hashshuffle、sortshuffle、钨丝shuffle,后者会进行排序,一个task一个文件,钨丝shuffle效果跟sort差不多, 使用了自己实现的一套内存管理机制,性能上有很大的提升。hashshuffle,map端写文件时每个task都会创建下一个stage总task数量的文件,可以设置合并,这样,每个excutor中的task就会公用一批文件,先往内存缓存写,再溢出到磁盘,调整大一些可以减少io次数,reduce端拉取文件时有buffer缓冲区,每次都只能拉取与buffer缓冲相同大小的数据。{lamp/}调优 Spark优化还包括,设置kyro序列化方式 ,性能更高、调整RDD持久化内存比例、调整shuffle时reduce端拉取数据重试次数,等待时长(因为在JVM full gc时是stop the world,多尝试几次)、数据本地化等待时长。 -
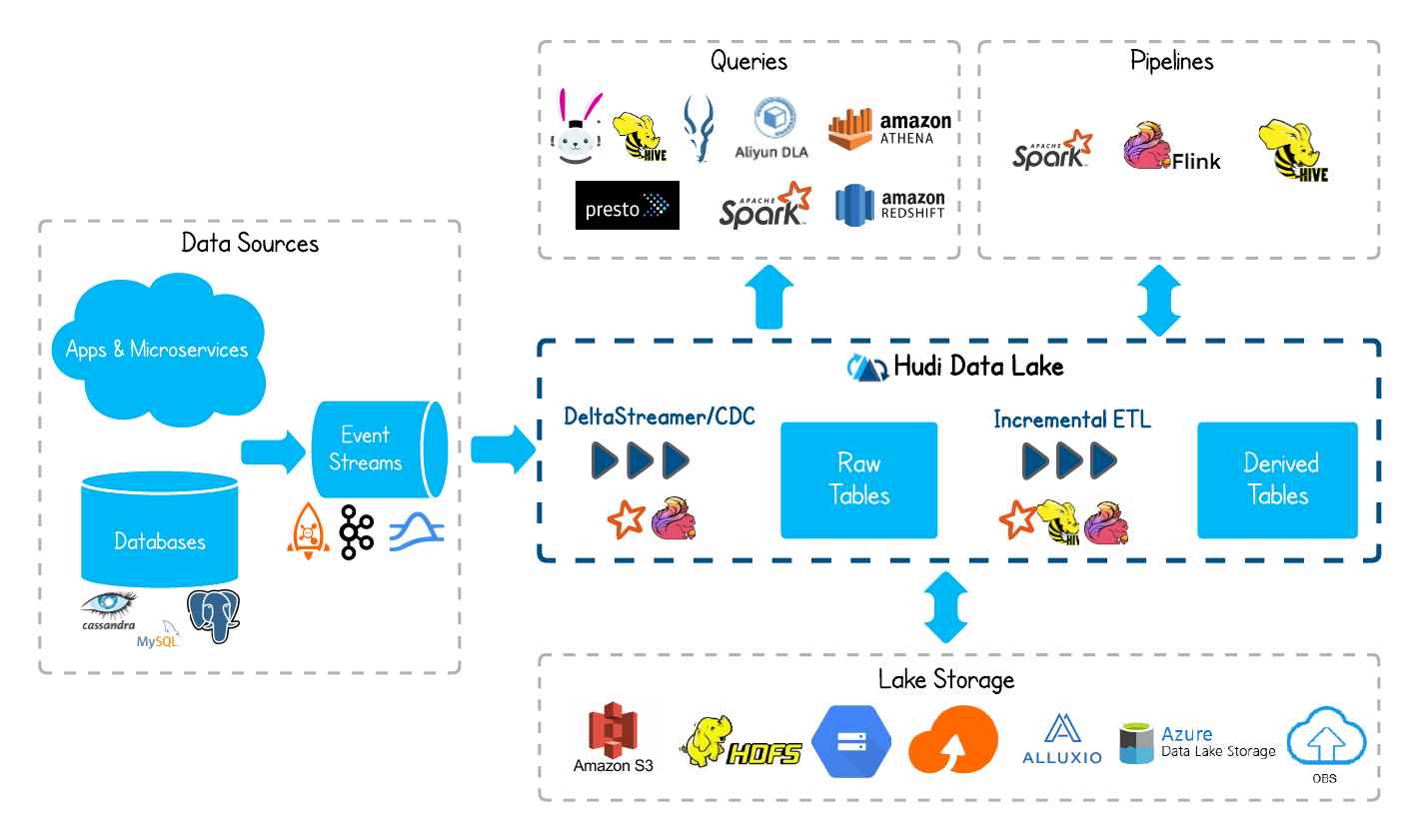
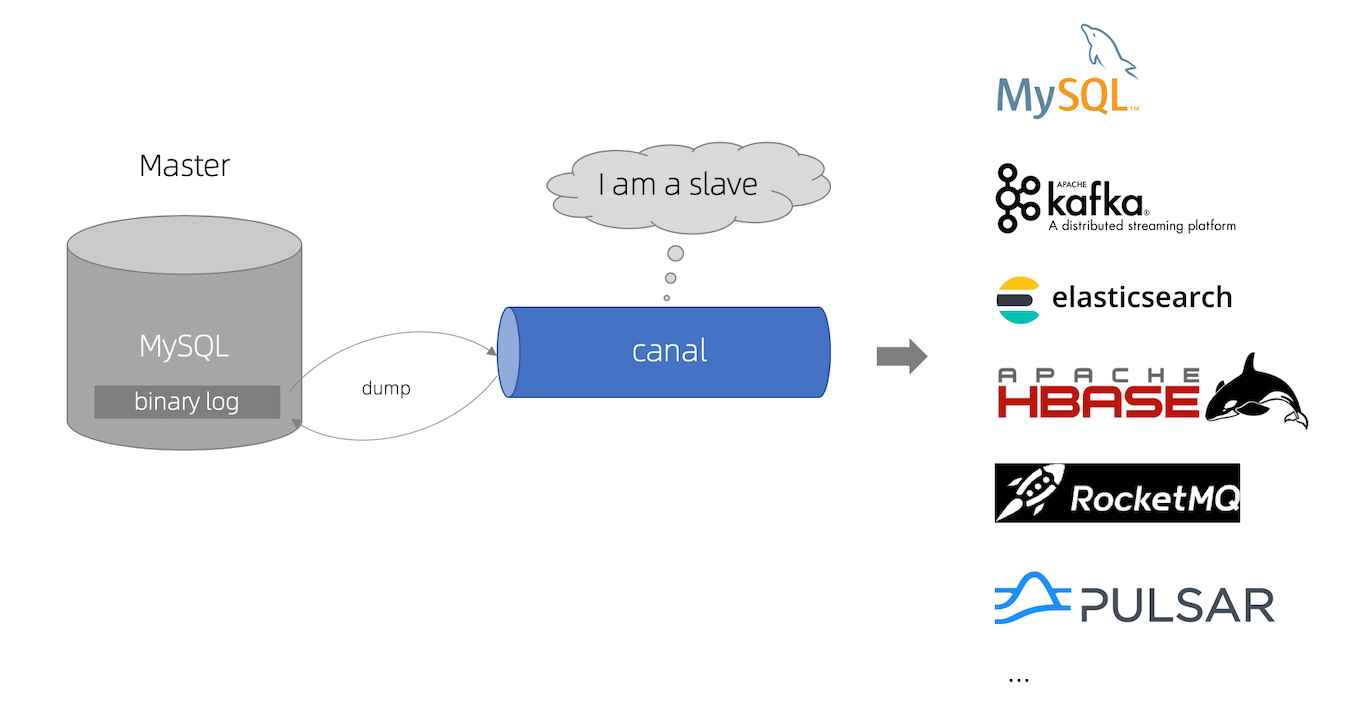
![数据同步工具DataX、Sqoop和Canal]()